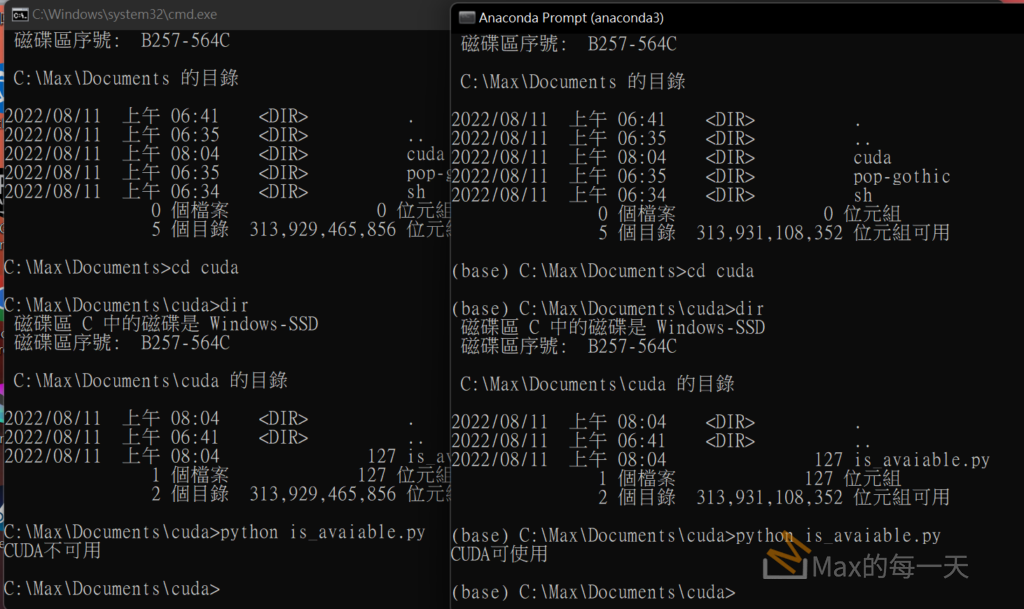
原本的程式是使用 for loop 去讀取某一個資料夾下的每一個檔案, 當檔案數到 4萬個的時候, 效率就變很差, 光讀取完4萬個檔案, 似乎就花了4分鐘, 因為 python 預設並不會使用 multi-thread 去開檔案.
改用 multi-thread 寫法之後, CPU 使用率直接上升為 100%, 程式效率變很好, 大約不到一分鐘就讀完並處理完 9萬個檔案.
完成程式碼, 主程式:
https://github.com/max32002/MaxFontScripts/blob/master/copy_lost_out.py
實際執行的副程式:
https://github.com/max32002/MaxFontScripts/blob/master/LibGlyph.py
for loop 寫法:
for f in files:
extension = splitext(f)
if extension[1] == '.glyph':
glyph_info = load_unicode_from_file(join(ff_folder,f), unicode_field)
unicode_info = 0
if 'unicode' in glyph_info:
unicode_info = glyph_info['unicode']
if check_altuni2:
if 'altuni2' in glyph_info:
altuni2_info = glyph_info['altuni2']
if len(altuni2_info) > 0:
altuni2_int = int(altuni2_info,16)
my_set.add(altuni2_int)
my_dict[altuni2_int] = f
if unicode_info > 0 and unicode_info < 0x110000:
my_set.add(unicode_info)
my_dict[unicode_info] = f multi-thread 寫法:
file_paths = [os.path.join(ff_folder, file) for file in os.listdir(ff_folder) if file.endswith('.glyph') and os.path.isfile(os.path.join(ff_folder, file))]
results = []
with concurrent.futures.ThreadPoolExecutor() as executor:
results = executor.map(load_unicode_from_file, file_paths, [unicode_field] * len(file_paths))
for glyph_info in results:
unicode_info = 0
if 'unicode' in glyph_info:
unicode_info = glyph_info['unicode']
if check_altuni2:
if 'altuni2' in glyph_info:
altuni2_info = glyph_info['altuni2']
if len(altuni2_info) > 0:
altuni2_int = int(altuni2_info,16)
my_set.add(altuni2_int)
my_dict[altuni2_int] = f
if unicode_info > 0 and unicode_info < 0x110000:
my_set.add(unicode_info)
file_name = os.path.basename(glyph_info["filepath"])
my_dict[unicode_info] = file_name