圖片驗證碼識別的可以分為幾個步驟,一般用 Pillow 庫或 OpenCV 來實現,取得圖片驗證碼文字的處理流程:
- 1.灰度處理&二值化
- 2.降噪
所謂降噪就是把不需要的信息通通去除,比如背景,干擾線,干擾像素等等,只留下需要識別的字符,讓圖片變成2進制點陣,方便代入模型訓練。 - 3.字符分割
- 4.標準化
- 5.識別 (OCR)
參考了這部教學影片:
[爬蟲實戰] 如何破解高鐵驗證碼 (1) – 去除圖片噪音點?
https://www.youtube.com/watch?v=6HGbKdB4kVY
python 用pip安装 cv2:
pip install opencv-python
說明:macOS 預設 python2 裡 numpy 的版本 numpy-1.8.0rc1,但 opencv 需要 1.11.1 以上,所以會安裝失敗,顯示:
ERROR: Cannot uninstall 'numpy'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
解法:
sudo python -m pip install numpy –ignore-installed numpy
sudo python -m pip install opencv-python
python 用pip安装 matplotlib:
pip install matplotlib
python 用pip安装 pytesseract:
pip install pytesseract
Tesseract OCR 安裝方法:
https://github.com/tesseract-ocr/tesseract/wiki
透過 selenium 的 element.screenshot() 即可取得驗證碼圖片:
https://selenium-python-zh.readthedocs.io/en/latest/api.html?highlight=screenshot#selenium.webdriver.remote.webelement.WebElement.screenshot
screenshot(filename)Saves a screenshot of the current element to a PNG image file. ReturnsFalse if there is any IOError, else returns True. Use full paths in your filename.
| Args: | filename: The full path you wish to save your screenshot to. This should end with a .png extension. |
|---|---|
| Usage: | element.screenshot(‘/Screenshots/foo.png’) |
Max取得到 screenshot:
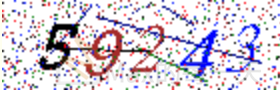
透過下面的python程式:
from PIL import Image,ImageDraw
image = Image.open("captcha.png").convert("L")
取得convert 為灰階後影像檔:

透過下面程式,用來2分化影像:
def binarizing(img,threshold): #input: gray image
pixdata = img.load()
w, h = img.size
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return img

降噪方案1:(不好用)
def depoint(img): #input: gray image
pixdata = img.load()
w,h = img.size
for y in range(1,h-1):
for x in range(1,w-1):
count = 0
if pixdata[x,y-1] > 245:
count = count + 1
if pixdata[x,y+1] > 245:
count = count + 1
if pixdata[x-1,y] > 245:
count = count + 1
if pixdata[x+1,y] > 245:
count = count + 1
if count > 2:
pixdata[x,y] = 255
return img
似乎只有使用 上/下/左/右 4個方向 shift 1點來判斷,如果遇到較大的噪會無效,處理結果:

效果似乎接近無效,因為黑點都略大。
改服用下面的程式碼:
#二值判断,如果确认是噪声,用改点的上面一个点的灰度进行替换
#该函数也可以改成RGB判断的,具体看需求如何
def getPixel(image,x,y,G,N):
L = image.getpixel((x,y))
if L > G:
L = True
else:
L = False
nearDots = 0
if L == (image.getpixel((x - 1,y - 1)) > G):
nearDots += 1
if L == (image.getpixel((x - 1,y)) > G):
nearDots += 1
if L == (image.getpixel((x - 1,y + 1)) > G):
nearDots += 1
if L == (image.getpixel((x,y - 1)) > G):
nearDots += 1
if L == (image.getpixel((x,y + 1)) > G):
nearDots += 1
if L == (image.getpixel((x + 1,y - 1)) > G):
nearDots += 1
if L == (image.getpixel((x + 1,y)) > G):
nearDots += 1
if L == (image.getpixel((x + 1,y + 1)) > G):
nearDots += 1
if nearDots < N:
return image.getpixel((x,y-1))
else:
return None
# 降噪
# 根据一个点A的RGB值,与周围的8个点的RBG值比较,设定一个值N(0 <N <8),当A的RGB值与周围8个点的RGB相等数小于N时,此点为噪点
# G: Integer 图像二值化阀值
# N: Integer 降噪率 0 <N <8
# Z: Integer 降噪次数
# 输出
# 0:降噪成功
# 1:降噪失败
def clearNoise(image,G,N,Z):
draw = ImageDraw.Draw(image)
for i in range(0,Z):
for x in range(1,image.size[0] - 1):
for y in range(1,image.size[1] - 1):
color = getPixel(image,x,y,G,N)
if color != None:
draw.point((x,y),color)
image.save("test4_clearNoise.jpg")
image = Image.open("captcha.png").convert("L")
image_binary = binarizing(image, 180)
clearNoise(image_binary,50,4,6)
結果是有比較好:
但上面的圖片,還是「無法」使用pytesseract 進行OCR 辨視成功:
code = pytesseract.image_to_string(image_binary, config='digits')
print("code:", code)
改用OpenCV 看看,OpenCV提供了這種技術的四種去噪方法:
https://docs.opencv.org/3.0-beta/modules/photo/doc/denoising.html
- cv2.fastNlMeansDenoising() – 使用單個灰度影象
- cv2.fastNlMeansDenoisingColored() – 使用彩色影象。
- cv2.fastNlMeansDenoisingMulti() – 用於在短時間內捕獲的影象序列(灰度影象)
- cv2.fastNlMeansDenoisingColoredMulti() – 與上面相同,但用於彩色影象。
基本的 opencv 使用範例:
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('die.png')
dst = cv2.fastNlMeansDenoisingColored(img,None,10,10,7,21)
plt.subplot(121),plt.imshow(img)
plt.subplot(122),plt.imshow(dst)
plt.show()
總結
Tesseract-ORC 對於這種弱驗證碼識別率還是可以,大部分字符能夠正確識別出來。只不過有時候會將數字 8 識別為 0。如果圖片驗證碼稍微變得復雜點,識別率大大降低,會經常識別不出來的情況。
如果想要做到識別率較高,那麽需要使用 CNN (Convolutional Neural Network,卷積神經網絡)或者 RNN (Recurrent Neural Network,循環神經網絡)訓練出自己的識別庫。正好機器學習很流行,學習一下也無妨。
卷積神經網路(Convolutional Neural Network, CNN)
CNN 也是模仿人類大腦的認知方式,譬如我們辨識一個圖像,會先注意到顏色鮮明的點、線、面,之後將它們構成一個個不同的形狀(眼睛、鼻子、嘴巴…),這種抽象化的過程就是CNN演算法建立模型的方式。卷積層(Convolution Layer) 就是由點的比對轉成局部的比對,透過一塊塊的特徵研判,逐步堆疊綜合比對結果,就可以得到比較好的辨識結果,過程如下圖。
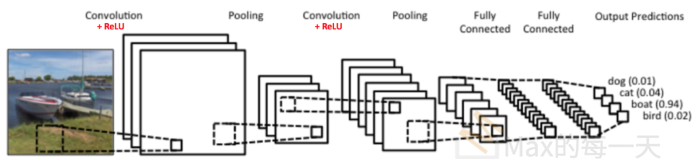
卷積層(Convolution Layer)
如何從點轉成面呢? 就是以圖像的每一點為中心,取周遭 N x N 格的點構成一個面(N 稱為 Kernel Size,N x N 的矩陣權重稱為『卷積核』),每一格給予不同的權重,計算加權總和,當作這一點的 output,再移動至下一點以相同方式處理,至圖像的最後一點為止,這就是 CNN 的卷積層(Convolution Layer)。
相關文章:CS231n: Convolutional Neural Networks for Visual Recognition
http://cs231n.github.io/convolutional-networks/
上面文章的「Convolution Demo」段落,它以動畫的方式說明取樣的方式,有助於更容易了解其原理。
卷積層處理方式與影像處理方法類似,採用滑動視窗(Sliding Window)運算,藉由給予『卷積核』不同的權重組合,就可以偵測形狀的邊、角,也有去除噪音(Noise)及銳化(Sharpen)的效果,萃取這些特徵當作辨識的依據,這也克服了迴歸(Regression)會受『異常點』(Outliers)嚴重影響推測結果的缺點。
資料來源:
Day 06:處理影像的利器 — 卷積神經網路(Convolutional Neural Network)
https://ithelp.ithome.com.tw/articles/10191820
循環神經網路(Recurrent Neural Network, RNN)
語言通常要考慮前言後語,以免斷章取義,也就是說,建立語言的相關模型,如果能額外考慮上下文的關係,準確率就會顯著提高,因此,學者提出『循環神經網路』(Recurrent Neural Network, RNN)演算法,它是『自然語言處理』領域最常使用的 Neural Network 模型。
相關文章:
速記AI課程-深度學習入門(二)
https://medium.com/@baubibi/%E9%80%9F%E8%A8%98ai%E8%AA%B2%E7%A8%8B-%E6%B7%B1%E5%BA%A6%E5%AD%B8%E7%BF%92%E5%85%A5%E9%96%80-%E4%BA%8C-954b0e473d7f
我發現,網路上很多AI相關的「入門」等級的教學文章,還滿容易懂和實作的。
相關影片:
1:[爬蟲實戰] 如何使用Selenium 抓取驗證碼?
https://www.youtube.com/watch?v=hF-dJj559ug
2:[爬蟲實戰] 如何破解高鐵驗證碼 (1) – 去除圖片噪音點?
https://www.youtube.com/watch?v=6HGbKdB4kVY
3:[爬蟲實戰] 如何破解高鐵驗證碼 (2) – 使用迴歸方法去除多餘弧線?
https://www.youtube.com/watch?v=4DHcOPSfC4c
上面影片的原始碼:
實作基於CNN的台鐵訂票驗證碼辨識以及透過模仿及資料增強的訓練集產生器 (Simple captcha solver based on CNN and a training set generator by imitating the style of captcha and data augmentation)
https://github.com/JasonLiTW/simple-railway-captcha-solver