MA-Font 中使用的 Multi-Head Attention Module 與 Self-Attention (SA) 的差異,可以從它們的定義、核心概念、以及在實際應用上的區別來詳細說明。簡單來說,Self-Attention 可以被視為 Multi-Head Attention 的一種特殊情況,它們之間存在著包含與被包含的關係。
為了更清晰地理解它們之間的差異,我們將從以下幾個方面逐一解析:
1. 基本定義與核心概念:
- Multi-Head Attention (多頭注意力機制):
- 核心概念: Multi-Head Attention 是一種更廣泛的注意力機制架構,它允許模型 同時從多個不同的「角度」 ( heads ) 去關注輸入資訊,並整合來自不同角度的注意力結果。 想像一下,就像是多個人從不同的視角觀察同一個物體,然後彙整各自的觀察結果,以更全面地理解這個物體。
- 組成結構: Multi-Head Attention Module 主要包含以下幾個關鍵組件:
- 線性投影層 (Linear Projections): 針對 Query (查詢), Key (鍵值), Value (數值) 各自進行線性轉換,將它們投影到不同的子空間。 這些投影後的版本會被每個 “head” 使用。
- 縮放點積注意力 (Scaled Dot-Product Attention): 這是每個 “head” 內部的注意力計算方式。 它通過計算 Query 和 Key 之間的點積來衡量它們的相關性,然後使用 Softmax 函數對這些相關性分數進行正規化,得到注意力權重。 這些權重會被用於加權求和 Value,得到該 head 的注意力輸出。
- 頭部拼接 (Concatenate Heads): 將所有 “head” 的注意力輸出 拼接 在一起。
- 輸出線性投影層 (Output Linear Projection): 對拼接後的結果再進行一次線性投影,將維度轉換回所需的輸出維度。
- 彈性與通用性: Multi-Head Attention 是一個非常彈性且通用的模組。 它可以被應用於各種不同的情境,並且 Query, Key, Value 的來源可以是不同的,這賦予了 Multi-Head Attention 極大的靈活性。
- Self-Attention (自注意力機制):
- 核心概念: Self-Attention 是注意力機制的一種 特殊形式。 它的特殊之處在於,用於計算注意力的 Query (查詢), Key (鍵值), 和 Value (數值) 都來自於 同一個輸入序列。 「Self-Attention」中的 “Self” 指的就是 針對自身輸入序列進行注意力計算。 想像一下,就像是在一句話中,每個詞語都去關注句子中的其他詞語,以理解詞語之間的相互關係和句子的整體語義。
- 組成結構: Self-Attention 的結構與 Multi-Head Attention 非常相似,它們都包含線性投影層、縮放點積注意力、頭部拼接和輸出線性投影層。 唯一的關鍵區別在於輸入。
- Query = Key = Value = 同一個輸入序列
- 專注於內部關係:Self-Attention 主要用於 捕捉一個序列內部不同位置之間的相互依賴關係。 例如,在自然語言處理中,Self-Attention 可以幫助模型理解句子中不同詞語之間的語法和語義關係;在圖像處理中,Self-Attention 可以幫助模型理解圖像不同區域之間的關聯性。
2. 關鍵差異:Query, Key, Value 的來源
Multi-Head Attention 和 Self-Attention 最核心的差異點就在於 Query, Key, Value 這三個輸入的來源。
- Self-Attention: Q, K, V 源自同一處
- Query, Key, Value <– Same Input Sequence / Feature Representation
- Self-Attention 專注於 序列內部 的注意力,也就是說,序列中的每個元素 (例如,一個詞語,圖像中的一個 patch) 都會與序列中的其他元素 (包括自身) 計算注意力。
- 適用情境: 捕捉序列內部不同位置之間的依賴關係,例如:
- 機器翻譯中的 Transformer 模型: 在編碼器和解碼器內部,使用 Self-Attention 來理解源語言句子和目標語言句子的內部結構。
- 圖像辨識中的 Vision Transformer (ViT): 將圖像分割成 patch 序列,然後使用 Self-Attention 來捕捉不同 patch 之間的關係,理解圖像的整體結構。
- Multi-Head Attention (更廣義的 Attention): Q, K, V 可以來自不同來源
- Query <– 來自一個輸入源 (Source 1)
- Key, Value <– 來自另一個輸入源 (Source 2) 或 與 Query 相同 (Source 1)
- Multi-Head Attention 更加通用,它可以處理更複雜的注意力模式,例如:
- Self-Attention (當 Query, Key, Value 都來自同一輸入源時,Multi-Head Attention 就退化成了 Self-Attention)。
- Encoder-Decoder Attention (編碼器-解碼器注意力): 在機器翻譯等序列到序列模型中,解碼器 (Decoder) 的 Query 來自於當前已生成的目標語言序列,而 Key 和 Value 則來自於編碼器 (Encoder) 輸出的源語言句子的表示。 這種注意力機制用於建立源語言和目標語言之間的對應關係。
- Cross-Attention (跨注意力): 更廣泛的應用情境,Query 和 Key/Value 來自不同的輸入,用於計算兩個不同輸入源之間的關聯性。
3. MA-Font 的 Multi-Head Attention Module 情境:
在 MA-Font 論文中,雖然論文標題或主要描述中可能沒有明確強調 “Self-Attention”,但在 風格編碼器 (Style Encoder) 中使用 Multi-Head Attention Module 來處理風格樣本 (few-shot style examples) 時,很可能包含了 Self-Attention 的成分。
以下是幾種可能的 MA-Font 風格編碼器中使用 Multi-Head Attention 的情境,以及 Self-Attention 在其中的作用:
- 情境 1: 風格樣本內部特徵的自注意力 (Self-Attention within Style Features)
- 機制: 風格編碼器首先使用 CNN 等網路提取 單個風格樣本圖像 的特徵圖 (feature map)。 然後,將這個特徵圖展平成序列,並將其同時作為 Query, Key, 和 Value 輸入到 Multi-Head Attention Module 中。
- Self-Attention 的作用: 在這個情境下,Multi-Head Attention Module 實際上是在執行 Self-Attention。 它讓模型能夠關注 單個風格樣本圖像內部不同區域或不同特徵之間的相互關係。 例如,讓模型學習到字體的筆畫在不同位置是如何相互關聯、共同構成特定風格的。 Multi-Head 的多個 heads 可以從不同角度捕捉這些內部關聯性。
- 輸出: Multi-Head Attention 的輸出會被進一步處理 (例如通過池化層) 得到風格向量,用於引導字體生成。
- 情境 2: 多個風格樣本之間的跨樣本注意力 (Cross-Sample Attention across Style Examples)
- 機制: MA-Font 方法通常會利用 少量 (few-shot) 的風格樣本 (例如,同一個風格的幾個不同字符圖像)。 在這種情境下,可以將 不同風格樣本的特徵表示 作為 Multi-Head Attention 的不同輸入。 例如:
- Query: 來自 第一個風格樣本 的特徵表示。
- Key, Value: 來自 所有風格樣本 (包括第一個樣本以及其他少量樣本) 的特徵表示。
- Cross-Attention 的作用: 此時,Multi-Head Attention Module 執行的是一種 跨樣本的注意力 (Cross-Attention)。 它讓模型能夠 學習不同風格樣本之間的共性與差異,從而更全面、更robust地理解目標風格。 模型可以通過 Query (例如,第一個樣本) 去關注 Key/Value (所有樣本),學習到哪些特徵在所有風格樣本中都比較重要 (共性),哪些特徵是特定樣本獨有的 (差異)。
- 融合多樣本信息: Multi-Head 的多個 heads 可以關注不同樣本之間的不同類型關聯,更有效地融合多個風格樣本的信息,產生更具代表性的風格向量。
- 機制: MA-Font 方法通常會利用 少量 (few-shot) 的風格樣本 (例如,同一個風格的幾個不同字符圖像)。 在這種情境下,可以將 不同風格樣本的特徵表示 作為 Multi-Head Attention 的不同輸入。 例如:
- 情境 3: 結合 Self-Attention 和 Cross-Attention (混合模式)
- 機制: 更複雜的模型可能會 結合使用 Self-Attention 和 Cross-Attention。 例如:
- 先對 每個風格樣本 進行 Self-Attention,提取每個樣本內部的風格特徵。
- 然後,使用 Cross-Attention 來融合 不同風格樣本 的 Self-Attention 輸出。 例如,將第一個樣本的 Self-Attention 輸出作為 Query,將所有樣本的 Self-Attention 輸出作為 Key/Value,進行跨樣本的注意力計算。
- 更精細的風格建模: 這種混合模式可以讓模型既能深入理解 單個風格樣本內部的特徵關聯,又能有效 融合多個風格樣本之間的共性信息,實現更精細、更全面的風格建模。
- 機制: 更複雜的模型可能會 結合使用 Self-Attention 和 Cross-Attention。 例如:
4. 總結:Self-Attention 是 Multi-Head Attention 的特例,MA-Font 可能同時利用兩者
- Self-Attention 是 Multi-Head Attention 的一個子集: 當 Multi-Head Attention 的 Query, Key, Value 都來自同一個輸入時,它就變成了 Self-Attention。 因此,Self-Attention 可以說是 Multi-Head Attention 的一種特殊配置。
- MA-Font 可能在風格編碼器中同時使用 Self-Attention 和 Cross-Attention: 為了更有效地進行少樣本字體風格生成,MA-Font 的風格編碼器很可能會 綜合利用 Self-Attention 和 Cross-Attention 的優勢。
- 使用 Self-Attention 來理解 單個風格樣本內部的特徵。
- 使用 Cross-Attention 來 融合多個風格樣本之間的共性。
- 通過 Multi-Head 機制,從多個角度捕捉風格的複雜性和多樣性。
- 實作時需參考 MA-Font 論文細節: 要確切了解 MA-Font 如何使用 Attention 機制,最關鍵的還是要 仔細研讀 MA-Font 論文原文。 論文中應該會詳細描述風格編碼器的網路結構,以及 Attention Module 的具體應用方式 (例如,是 Self-Attention 還是 Cross-Attention,以及 Query, Key, Value 的具體來源)。 根據論文的描述,才能更精準地實作 MA-Font 的 Multi-Head Attention Module。
總之,理解 Multi-Head Attention 和 Self-Attention 的關係,以及它們在不同情境下的應用方式,對於深入理解 MA-Font 這類基於注意力機制的少樣本字體生成模型至關重要。 在實作時,需要根據論文的具體設計,靈活地運用 Self-Attention 和 Multi-Head Attention 的概念,才能達到最佳的風格遷移和生成效果。
chatgpt 回答:
Multi-Head Attention (MHA) 與 Self-Attention (SA) 的差異主要在於注意力計算的方式與多頭機制的應用。我們可以從 結構、計算方式、應用場景 三個角度來比較。
📌 1. 結構上的差異
Self-Attention(SA,單頭注意力機制)
- 輸入: 內容特徵(Content Features)
- 計算方式:
- 使用單一組 Query (Q)、Key (K)、Value (V) 計算注意力分數
- 透過 Softmax 加權後取得最終輸出
- 優勢: 能夠學習全局關係
- 缺點: 計算維度受限,難以捕捉不同層次的特徵
💡 SA 公式:
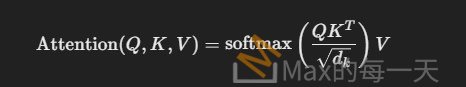
其中:
- Query (Q):代表輸入特徵,希望從風格圖像中學習的資訊。
- Key (K):風格圖像的特徵,用於與 Query 進行相似度計算。
- Value (V):從風格圖像提取的特徵,根據相似度加權後用於字體風格生成。
Multi-Head Attention(MHA,多頭注意力機制)
- 輸入: 內容特徵(Content Features) & 風格特徵(Style Features)
- 計算方式:
- 多組 Query、Key、Value(Q, K, V),將輸入特徵拆分成 多個 Head 進行獨立學習
- 每個 Head 可以學習不同的特徵維度
- 最後將所有 Head 的輸出 拼接 (Concat) 起來,並經過線性變換得到最終輸出
- 優勢:
- 每個 Head 可以學習不同的風格細節(局部 & 全局特徵)
- 更能捕捉複雜的字體風格轉換
- 缺點: 計算量較大,需要額外的計算資源
💡 MHA 公式:
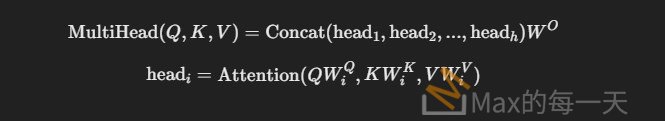
其中:
- WiQ,WiK,WiV 是學習參數矩陣
- h 是多頭數量
- W^O 是最終輸出的線性變換矩陣
📌 2. 計算方式的差異
| 方式 | Self-Attention (SA) | Multi-Head Attention (MHA) |
|---|---|---|
| 頭數 | 單頭(1個 Q, K, V) | 多頭(多組 Q, K, V) |
| 輸出維度 | 與輸入維度相同 | 經過拼接與線性變換 |
| 學習能力 | 學習單一特徵關係 | 學習多種不同的特徵關係 |
| 適用場景 | 風格特徵匹配(單一風格) | 風格融合與遷移(複合風格) |
💡 簡單來說,MHA 是 SA 的擴展版本,可以讓模型學習更多風格層次的信息!
📌 3. 在 MA-Font 中的應用差異
在 MA-Font 的 Multi-Head Attention Module 中:
- Self-Attention(單頭注意力):適合應用於小型風格變換,例如單個風格字體的生成。
- Multi-Head Attention(多頭注意力):能更全面地學習多種風格特徵,特別適用於少樣本字體風格轉換,因為:
- 不同 Head 負責不同的風格細節(如筆劃形狀、字體間距、筆畫粗細等)
- 多頭機制能讓不同風格更好地融合,生成更自然的結果
- 可以對應不同語言的字體風格,例如中、英、日文的字體風格遷移
📌 總結
✔ Self-Attention (SA):
- 單頭注意力
- 只能學習一種風格特徵關係
- 適合基礎字體匹配
✔ Multi-Head Attention (MHA):
- 多頭注意力,可以學習 多種風格細節
- 適合 跨語言字體風格遷移(不同語言之間的風格學習)
- 提升字體生成的細膩度與適應能力
在 MA-Font 的應用場景中,Multi-Head Attention 比 Self-Attention 更有優勢,因為它可以更有效地處理 複雜字體風格的變換,尤其是少樣本學習的情境。