在 zi2zi-pytorch 的 infer 時, 訓練資料由原本的 256×256 修改為 512×512, 顯示錯誤訊息:
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 888.00 MiB. GPU 0 has a total capacity of 4.00 GiB of which 0 bytes is free. Of the allocated memory 5.21 GiB is allocated by PyTorch, and 450.33 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation.
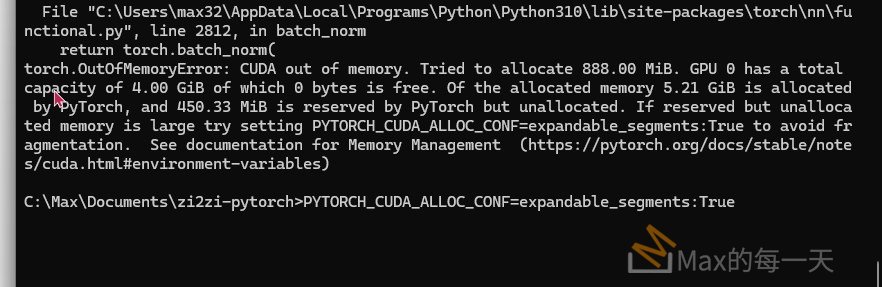
解法:
這個錯誤訊息 torch.OutOfMemoryError: CUDA out of memory 表示在執行 zi2zi-pytorch 的推論 (infer) 程式碼時,您的 GPU 記憶體不足以分配所需的空間。當您將訓練資料的尺寸從 256×256 增加到 512×512 時,模型的記憶體需求也隨之增加,導致 GPU 記憶體耗盡。
讓我逐步解釋錯誤訊息並提供幾種解決方案:
錯誤訊息解析:
torch.OutOfMemoryError: CUDA out of memory: 這是核心錯誤,表示 CUDA (NVIDIA 的 GPU 運算平台) 記憶體不足。Tried to allocate 888.00 MiB: 程式碼嘗試分配 888.00 MiB (MegaBytes) 的記憶體,但失敗了。GPU 0 has a total capacity of 4.00 GiB: 您的 GPU (編號為 0 的 GPU) 總共有 4.00 GiB (GigaBytes) 的記憶體容量。of which 0 bytes is free: 目前 GPU 記憶體中 完全沒有剩餘空間 (0 bytes free)。這是造成錯誤的直接原因。Of the allocated memory 5.21 GiB is allocated by PyTorch: PyTorch 已經分配了 5.21 GiB 的記憶體。 這個數值大於 GPU 的總容量 4.00 GiB,這可能看起來有點奇怪,但實際上可能包含 PyTorch 預先保留但尚未完全使用的記憶體,或者其他記憶體管理機制。 重要的是,訊息指出記憶體已經被大量佔用。and 450.33 MiB is reserved by PyTorch but unallocated: PyTorch 還預留了 450.33 MiB 的記憶體,但尚未實際分配。 當預留但未分配的記憶體很大時,錯誤訊息建議嘗試設定環境變數PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True,這有時可以幫助減少記憶體碎片化。
解法:
由於錯誤訊息明確指出 GPU 記憶體不足,主要解法方向是 減少 GPU 記憶體的使用量。 以下列出幾種常見的解決方案,您可以根據您的情況嘗試:
- 降低 Batch Size (最常見且最有效的解法)
- 原因: Batch size (批次大小) 決定了模型一次處理多少張圖像。 較大的 batch size 可以提高 GPU 的利用率,但同時也會消耗更多記憶體。 在推論 (infer) 時,通常不需要太大的 batch size,甚至 batch size 為 1 也是可以接受的。
- 解法: 在
infer.py腳本中,檢查DataLoader的設定 (如果有的話),或者在模型進行推論的程式碼部分, 將 batch size 減小。 例如,如果原本的 batch size 是 8 或更大,嘗試將其設定為 1 或 2。 Python# 假設您在 infer.py 中使用了 DataLoader dataloader = DataLoader(infer_dataset, batch_size=1, shuffle=False) # 將 batch_size 設定為 1 # ... 或者在進行模型推論時,確保一次只處理一張圖像
- 減小輸入圖像尺寸 (如果可以接受較低的解析度)
- 原因: 較大的圖像尺寸會導致中間特徵圖 (feature map) 的尺寸也變大,進而增加記憶體消耗。
- 解法: 如果您不需要 512×512 這麼高的解析度,可以 將輸入圖像的尺寸重新調整回 256×256 或更小的尺寸。 您需要在
infer.py腳本中,在讀取圖像後、輸入模型之前,加入圖像縮放 (resize) 的步驟。 Pythonfrom torchvision import transforms from PIL import Image # ... 讀取圖像 img ... (假設讀取到 PIL Image 物件 img) transform = transforms.Compose([ transforms.Resize((256, 256)), # 將圖像縮放至 256x256 transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 假設您有 Normalize 操作 ]) img = transform(img) # 對圖像進行轉換,包括 Resize # ... 將 img 輸入模型 ...
- 清理 GPU 記憶體 (嘗試釋放可能未被有效釋放的記憶體)
- 原因: 有時候,即使程式碼已經執行完畢,GPU 記憶體可能沒有被完全釋放。 嘗試清理記憶體可能有助於解決問題。
- 解法: 在執行
infer.py之前,嘗試執行以下程式碼來清理 PyTorch 的 CUDA 記憶體快取: Pythonimport torch torch.cuda.empty_cache()您可以將這段程式碼加在infer.py腳本的最前面,或者在執行infer.py之前,先在 Python 環境中執行一次。
- 使用更小的模型 (如果模型複雜度過高)
- 原因: 更複雜的模型 (例如,層數更多、參數更多) 通常需要更多的記憶體。
- 解法: 如果您可以接受一定程度的效能損失 (生成品質可能略微下降),可以考慮 使用更小的模型架構。 例如,減少
UNetGenerator中的num_downs參數,或者減小卷積層的ngf(number of generator filters) 或ndf(number of discriminator filters) 參數,以降低模型的複雜度。 注意:修改模型架構通常需要重新訓練模型。
- 使用 Mixed Precision (混合精度運算) (進階方法,可能不適用於所有情況)
- 原因: Mixed Precision (例如 FP16, 半精度浮點數) 可以顯著減少模型運算時的記憶體佔用,並可能加速運算 (在支援 Tensor Cores 的 GPU 上)。
- 解法: 如果您對 PyTorch 的進階用法比較熟悉,可以嘗試在
infer.py腳本中啟用 Mixed Precision 推論。 PyTorch 提供了torch.cuda.amp(Automatic Mixed Precision) 工具來簡化 Mixed Precision 的使用。 Pythonimport torch from torch.cuda.amp import autocast # ... 模型載入, 資料準備 ... with torch.no_grad(): # 推論階段不需要計算梯度 with autocast(): # 啟用 Mixed Precision output = generator(input_data) # 執行模型前向傳播 # ... 後續處理 ...注意:Mixed Precision 可能會帶來一些數值穩定性方面的問題,需要仔細測試和驗證。 此外,Mixed Precision 的加速效果和記憶體節省程度取決於您的 GPU 是否支援 Tensor Cores 和模型的具體架構。
- 使用 CPU 進行推論 (最後的選擇,效能會大幅下降)
- 原因: 如果以上方法都無法解決記憶體問題,且您只有 4GB 記憶體的 GPU,最後的選擇是 放棄使用 GPU,改用 CPU 進行推論。 CPU 記憶體 (系統記憶體) 通常比 GPU 記憶體大得多,不太容易遇到 Out of Memory 錯誤。
- 解法: 在
infer.py腳本中,將模型和資料都移動到 CPU 上 (例如,使用model.to('cpu')和input_data.to('cpu'))。 警告:使用 CPU 推論速度會比 GPU 慢很多,可能難以接受。 只有在萬不得已的情況下才考慮這個方案。
- 嘗試設定環境變數
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True(效果可能有限)- 原因: 如錯誤訊息建議,設定這個環境變數有時可以幫助減少記憶體碎片化,從而讓 PyTorch 更有效地利用 GPU 記憶體。
- 解法: 在執行
infer.py之前,在您的終端機或命令提示字元中設定環境變數:- Linux/macOS:
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True - Windows:
set PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
- Linux/macOS:
- 升級 GPU 硬件 (最直接但成本最高的解法)
- 原因: 最根本的解決方案是 升級您的 GPU 硬件,更換為擁有更多記憶體的 GPU (例如,8GB, 12GB, 24GB 甚至更多)。
- 解法: 購買並安裝具有更大記憶體容量的 NVIDIA GPU。 這是最直接、最徹底的解決方案,但也是成本最高的。
推薦的優先順序:
- 優先嘗試方案 1: 降低 Batch Size。 這是最簡單、最有效且通常不會顯著影響生成品質的解法。
- 如果方案 1 無效或效果不佳,嘗試方案 2: 減小輸入圖像尺寸。 這是一種權衡方案,可能會降低生成圖像的細節程度,但可以有效降低記憶體需求。
- 可以嘗試方案 3: 清理 GPU 記憶體快取,以及方案 7: 設定環境變數,看看是否能擠出一些額外的記憶體空間。 這兩個方案比較簡單,可以快速嘗試,但效果可能有限。
- 如果以上方案都無法解決問題,且您對模型結構比較熟悉,可以考慮方案 4: 使用更小的模型。 但這需要重新訓練模型,且可能影響生成品質。
- 方案 5: Mixed Precision 可以作為進階選項嘗試,但需要謹慎評估其穩定性和效果。
- 方案 6: 使用 CPU 推論 作為最後的退路,但要意識到效能會大幅下降。
- 方案 8: 升級 GPU 硬件 是最徹底的解決方案,但需要額外的預算。
請按照上述優先順序,逐步嘗試這些解法。 通常情況下,降低 Batch Size 或減小輸入圖像尺寸 就能解決 torch.OutOfMemoryError 問題。 在嘗試任何方案後,請務必重新執行 infer.py 腳本,觀察錯誤是否消失。