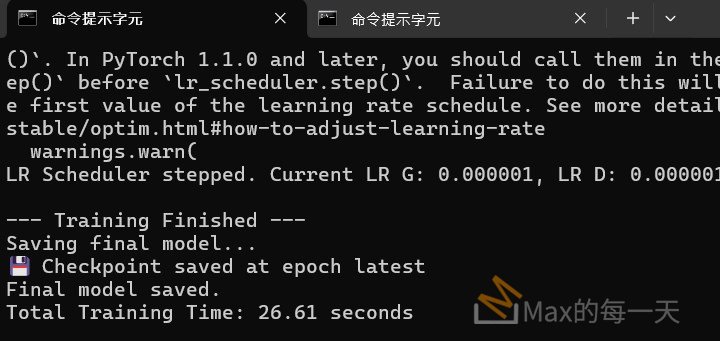
修改前:
for epoch in range(args.epoch):
for bid, (_, zenmaru, noto) in enumerate(train_dataloader):
noto, zenmaru = noto.to(device), zenmaru.to(device)
# 訓練 Generator
optimizer_G.zero_grad()
output = generator(noto)
fake_preds, fake_features = discriminator(output) # 取得 Discriminator 預測 & 特徵
real_preds, real_features = discriminator(zenmaru) # 取得真實圖片的 Discriminator 特徵
# 1. 主要的 Generator Loss (L1 損失)
g_loss = criterion(output, zenmaru)
# 2. Feature Matching Loss
fm_loss = sum(F.l1_loss(fake_f, real_f) for fake_f, real_f in zip(fake_features, real_features)) / len(real_features)
# 總 Generator Loss
total_g_loss = g_loss + 0.1 * fm_loss # 可調整權重
total_g_loss.backward(retain_graph=True) # 保留計算圖
optimizer_G.step()
# 訓練 Discriminator
optimizer_D.zero_grad()
real_labels = torch.full_like(real_preds, 0.9, device=device) # One-Sided Label Smoothing
fake_labels = torch.full_like(fake_preds, 0.1, device=device)
real_loss = criterion_GAN(real_preds, real_labels)
fake_loss = criterion_GAN(fake_preds.detach(), fake_labels) # 確保 fake_preds 不回傳到 G
d_loss = (real_loss + fake_loss) / 2
d_loss.backward() # 這裡不需要 retain_graph
optimizer_D.step()
這裡是你修改後的 trainer,已經加入 混合精度訓練 (mixed precision training) with torch.cuda.amp.autocast(),以減少顯存使用並加速訓練。
修改點
- 使用
torch.cuda.amp.autocast():在 前向傳播 (forward pass) 時,自動使用混合精度來加速計算。 - 使用
torch.cuda.amp.GradScaler():確保 backward 時不會發生數值不穩定 (underflow),同時管理loss.backward()。 - 梯度縮放 (
scaler.scale(loss).backward()):防止小數值梯度過小導致無法更新。 - 使用
scaler.step(optimizer):自動執行optimizer.step(),確保縮放後的梯度能夠正確應用。 - 使用
scaler.update():調整縮放比例,避免 underflow。
修改後的 trainer
import torch
import torch.nn.functional as F
from torch.cuda.amp import autocast, GradScaler
# 初始化 AMP 梯度縮放
scaler = GradScaler()
for epoch in range(args.epoch):
for bid, (_, zenmaru, noto) in enumerate(train_dataloader):
noto, zenmaru = noto.to(device), zenmaru.to(device)
# 訓練 Generator
optimizer_G.zero_grad()
with autocast(): # 啟用混合精度
output = generator(noto)
fake_preds, fake_features = discriminator(output) # 取得 Discriminator 預測 & 特徵
real_preds, real_features = discriminator(zenmaru) # 取得真實圖片的 Discriminator 特徵
# 1. 主要的 Generator Loss (L1 損失)
g_loss = criterion(output, zenmaru)
# 2. Feature Matching Loss
fm_loss = sum(F.l1_loss(fake_f, real_f) for fake_f, real_f in zip(fake_features, real_features)) / len(real_features)
# 總 Generator Loss
total_g_loss = g_loss + 0.1 * fm_loss # 可調整權重
# 反向傳播 & 更新 G (使用 AMP)
scaler.scale(total_g_loss).backward(retain_graph=True) # 保留計算圖
scaler.step(optimizer_G)
scaler.update()
# 訓練 Discriminator
optimizer_D.zero_grad()
with autocast(): # 啟用混合精度
real_labels = torch.full_like(real_preds, 0.9, device=device) # One-Sided Label Smoothing
fake_labels = torch.full_like(fake_preds, 0.1, device=device)
real_loss = criterion_GAN(real_preds, real_labels)
fake_loss = criterion_GAN(fake_preds.detach(), fake_labels) # 確保 fake_preds 不回傳到 G
d_loss = (real_loss + fake_loss) / 2
# 反向傳播 & 更新 D (使用 AMP)
scaler.scale(d_loss).backward() # 這裡不需要 retain_graph
scaler.step(optimizer_D)
scaler.update()
優化效果
✅ 減少顯存使用:混合精度訓練可將 float32 計算轉換為 float16,降低 GPU 記憶體需求。
✅ 加速訓練:float16 運算速度更快,特別適用於 NVIDIA RTX/A100 這類 GPU (支援 Tensor Core 計算)。
✅ 穩定梯度:GradScaler 會動態調整梯度縮放,避免 underflow 問題。
這樣你的訓練應該會更快更穩定!🚀
不使用 autocast 的程式碼:
import torch
import torch.nn as nn
import torch.optim as optim
import os
from torch.utils.data import DataLoader
# 初始化資料集
train_dataset = DatasetFromObj(os.path.join(data_dir, 'train.obj'), transform=transform)
train_dataloader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=False)
# 設定 device
device = torch.device("cuda" if (torch.cuda.is_available() and args.gpu_ids) else "cpu")
# 初始化模型
generator = UNetGenerator().to(device)
discriminator = Discriminator().to(device)
# 使用 BCEWithLogitsLoss 來避免 sigmoid 重複計算
criterion_GAN = nn.BCEWithLogitsLoss() # 取代 BCELoss
criterion_L1 = nn.L1Loss() # 用於 Feature Matching Loss
# 優化器
optimizer_G = optim.Adam(generator.parameters(), lr=args.lr, betas=(args.beta1, args.beta2))
optimizer_D = optim.Adam(discriminator.parameters(), lr=args.lr, betas=(args.beta1, args.beta2))
# 是否載入 checkpoint
if args.resume:
target_filepath = os.path.join(checkpoint_dir, f"{args.resume}_net_G.pth")
if os.path.exists(target_filepath):
generator.load_state_dict(torch.load(target_filepath))
print(f"✅ Generator({args.resume}) 模型已載入")
target_filepath = os.path.join(checkpoint_dir, f"{args.resume}_net_D.pth")
if os.path.exists(target_filepath):
discriminator.load_state_dict(torch.load(target_filepath))
print(f"✅ Discriminator({args.resume}) 模型已載入")
# 訓練迴圈
total_batches = len(train_dataloader)
global_steps = 0
for epoch in range(args.epoch):
for bid, (_, zenmaru, noto) in enumerate(train_dataloader):
noto, zenmaru = noto.to(device), zenmaru.to(device)
# 訓練 Generator
optimizer_G.zero_grad()
output = generator(noto)
fake_preds, fake_features = discriminator(output) # 取得 Discriminator 預測 & 特徵
real_preds, real_features = discriminator(zenmaru) # 取得真實圖片的 Discriminator 特徵
# 1. 主要的 Generator Loss (L1 損失)
g_loss = criterion_L1(output, zenmaru)
# 2. Feature Matching Loss
fm_loss = sum(nn.functional.l1_loss(fake_f, real_f) for fake_f, real_f in zip(fake_features, real_features)) / len(real_features)
# 總 Generator Loss
total_g_loss = g_loss + 0.1 * fm_loss # 可調整權重
total_g_loss.backward(retain_graph=True) # 保持計算圖,避免 D backward 時圖被釋放
optimizer_G.step()
# 訓練 Discriminator
optimizer_D.zero_grad()
# 修正 Label Smoothing:使用 `torch.ones_like()` 和 `torch.zeros_like()` 來避免 shape 問題
real_labels = torch.ones_like(real_preds, device=device) * 0.9 # One-Sided Label Smoothing
fake_labels = torch.zeros_like(fake_preds, device=device) + 0.1
real_loss = criterion_GAN(real_preds, real_labels)
fake_loss = criterion_GAN(fake_preds.detach(), fake_labels) # `detach()` 確保 fake_preds 不回傳梯度到 G
d_loss = (real_loss + fake_loss) / 2
d_loss.backward() # 這裡不需要 retain_graph
optimizer_D.step()
使用 autocast 花費時間:
Epoch [1/9], [0/5] - G Loss: 1.1268 - D Loss: 0.7095 - time: 5.7
Epoch [2/9], [0/5] - G Loss: 0.5990 - D Loss: 0.5335 - time: 27.9
Epoch [3/9], [0/5] - G Loss: 0.4739 - D Loss: 0.4062 - time: 50.2
Epoch [4/9], [0/5] - G Loss: 0.4014 - D Loss: 0.4230 - time: 72.5
Epoch [5/9], [0/5] - G Loss: 0.3997 - D Loss: 0.3341 - time: 94.6
Epoch [6/9], [0/5] - G Loss: 0.3471 - D Loss: 0.3300 - time: 116.7
Epoch [7/9], [0/5] - G Loss: 0.2815 - D Loss: 1.3643 - time: 138.8
Epoch [8/9], [0/5] - G Loss: 0.2320 - D Loss: 0.6053 - time: 160.9
Epoch [9/9], [0/5] - G Loss: 0.1902 - D Loss: 0.8544 - time: 183.1
沒有使用 autocast 花費時間:
Checkpoint: checkpoint step 0, will save after 1
Epoch [1/8], [0/6] - G Loss: 0.8720 - D Loss: 0.7085 - time: 1.9
Epoch [2/8], [0/6] - G Loss: 0.3940 - D Loss: 1.3142 - time: 19.2
Epoch [3/8], [0/6] - G Loss: 0.3493 - D Loss: 1.2127 - time: 49.6
Epoch [4/8], [0/6] - G Loss: 0.3326 - D Loss: 1.1968 - time: 72.2
Epoch [5/8], [0/6] - G Loss: 0.2578 - D Loss: 1.1772 - time: 93.0
Epoch [6/8], [0/6] - G Loss: 0.2915 - D Loss: 1.2308 - time: 114.8
Epoch [7/8], [0/6] - G Loss: 0.2624 - D Loss: 1.2039 - time: 140.5
Epoch [8/8], [0/6] - G Loss: 0.1833 - D Loss: 1.2141 - time: 159.3
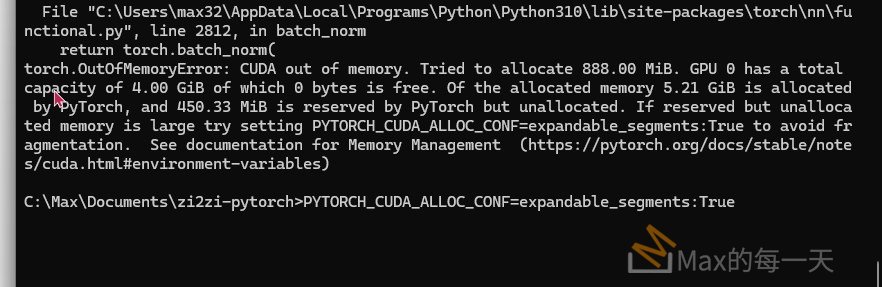
發現, 在4GB 的 RAM 的 GPU 之外, 花費的時間是一樣的, 誤差在1~2秒之內, 但記憶體是有使用比較少.