這2個模型實際上差少多時間?
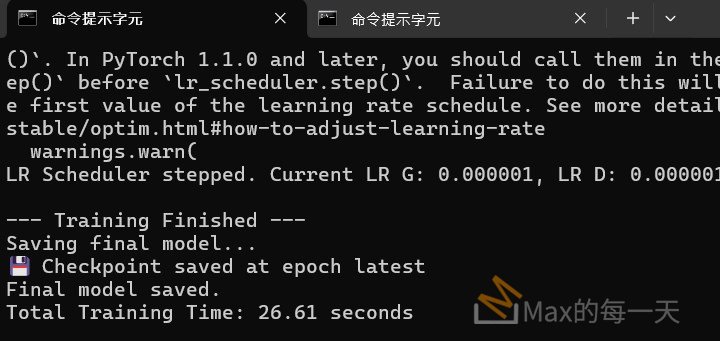
實際測試推論的效果, 沒有差太遠, 花費的時間, 訓練資料為11筆, 在 4GB 的筆電上執行, Self Attention 花費 28.15 秒, LinearAttention, 花費 26.61 秒.
在 colab 上, 每100個 checkpoint, 使用 attention_type=”linear” 是 238 秒, 使用 “self” 是 261 秒, 差 23秒, 大約增加 1/10 的速度, 滿可觀的!
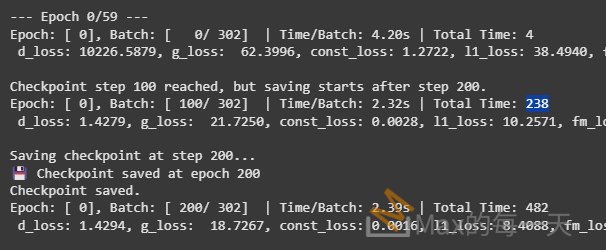
除此之外, 相同的 batch size 之下, 用的 GPU memory 更少.
要將之前使用 SelfAttention 訓練的模型的權重應用到使用 LinearAttention 的新模型上,您需要仔細地處理權重的對應關係,因為這兩個注意力機制的內部結構是不同的。
以下是逐步進行權重轉換的策略和程式碼範例:
策略:
- 載入舊模型的權重: 首先,載入您之前使用
SelfAttention訓練好的模型的權重。 - 創建新的模型結構: 創建一個新的模型實例,這個模型使用
LinearAttention替換了原來的SelfAttention。 - 比對模型結構和權重名稱: 檢查舊模型和新模型的層結構和權重名稱。
UnetSkipConnectionBlock中除了注意力機制之外的層(例如downconv,upconv,norm,style_mod等)的權重名稱應該是相同的。 - 映射和複製權重:
- 對於結構和權重名稱相同的層,可以直接將舊模型的權重複製到新模型中。
- 對於注意力機制相關的權重,由於
SelfAttention和LinearAttention的內部參數不同,無法直接複製權重。您需要決定如何處理這些權重。常見的做法是:- 重新初始化注意力機制的權重: 讓新的
LinearAttention層使用其預設的初始化方式。 - 不載入注意力機制的權重: 在載入權重時,忽略與
SelfAttention相關的權重。
- 重新初始化注意力機制的權重: 讓新的
- 載入部分權重到新模型: 使用
load_state_dict方法載入您映射和處理後的權重。設置strict=False參數,以允許載入部分權重。 - 微調(可選): 在載入部分權重後,您可能需要使用新的資料集對整個模型或僅注意力機制相關的層進行微調,以使模型適應新的注意力機制。
程式碼範例:
假設您的舊模型和新模型都包含 UnetSkipConnectionBlock,並且您想將舊模型中除了 SelfAttention 之外的權重載入到新模型中。
Python
import torch
import torch.nn as nn
import torch.nn.functional as F
# (您的 LinearAttention 和 SelfAttention 類別定義)
# (您的 UnetSkipConnectionBlock 和 UNetGenerator 類別定義)
# 1. 載入舊模型的權重
old_model_path = 'path/to/your/old_model.pth'
old_state_dict = torch.load(old_model_path)
# 2. 創建新的模型結構
new_model = UNetGenerator(
input_nc=1,
output_nc=1,
num_downs=8,
ngf=64,
embedding_num=40,
embedding_dim=128,
norm_layer=nn.InstanceNorm2d,
use_dropout=False,
self_attention=True, # 在新的模型中啟用 self_attention,它將使用 LinearAttention
blur=False
)
new_state_dict = new_model.state_dict()
# 3. 比對模型結構和權重名稱,並映射權重
pretrained_dict = {k: v for k, v in old_state_dict.items() if k in new_state_dict}
# 打印匹配的權重名稱,方便您了解哪些權重被成功映射
print("成功匹配並載入的權重:")
for name in pretrained_dict:
print(name)
# 4. 載入部分權重到新模型
new_model.load_state_dict(pretrained_dict, strict=False)
print("\n部分舊模型權重已載入到新模型。")
# (可選) 將新模型儲存起來
# new_model_save_path = 'path/to/save/new_model_with_partial_weights.pth'
# torch.save(new_model.state_dict(), new_model_save_path)
# (可選) 在新的資料上微調模型
# ... (您的訓練迴圈,可能需要調整學習率和訓練策略)
注意事項:
- 權重名稱的匹配: PyTorch 的
state_dict使用層的名稱作為鍵。只有當舊模型和新模型中對應層的名稱完全一致時,權重才能直接載入。 - 注意力機制的處理: 由於
SelfAttention和LinearAttention的參數名稱和數量都不同(例如,SelfAttention有scale參數,而LinearAttention沒有類似的直接對應),您無法直接將SelfAttention的權重載入到LinearAttention中。您需要接受重新初始化這些層的權重。 strict=False: 在load_state_dict中使用strict=False非常重要。這告訴 PyTorch,如果載入的state_dict中缺少新模型中的某些鍵(例如LinearAttention的權重),或者新模型中存在載入的state_dict中沒有的鍵(例如SelfAttention的權重),也不要拋出錯誤。- 微調: 由於注意力機制的改變可能會影響模型的整體行為,建議在載入部分權重後進行微調,尤其是在新的資料集上。您可以先使用較小的學習率進行微調。
- 模型結構的一致性: 確保除了注意力機制之外,新模型和舊模型的其他結構(例如卷積層、歸一化層、線性層)的超參數(通道數、核大小等)是相同的,這樣才能成功載入對應的權重。
通過以上步驟,您可以將舊模型中與新模型結構兼容的權重載入進來,並為新的 LinearAttention 層進行重新初始化或後續的微調。記住仔細檢查模型結構和權重名稱,以確保權重映射的正確性。