請求處理的瓶頸邏輯
當 Apache 面對大量連線時,即便 CPU 沒滿,使用者確實可能需要排隊。這通常是因為 Apache 的 mpm 設定限制了同時處理請求的數量(MaxRequestWorkers)。當請求超過這個值,後續的連線會被放在作業系統的 backlog 隊列中等待。如果這個隊列也滿了,使用者就會看到連線逾時或拒絕連線。
在高併發場景下,Apache 每個連線通常會佔用一個進程或線程,這非常消耗記憶體與 CPU 資源。即便你調整了核心網路參數,如果 Apache 本身的工人數量設得太低,連線進不來;設得太高,記憶體會耗盡導致系統瘋狂交換資料(Swap),進而讓 CPU 飆升到 100%。
記憶體與 Swap 的警訊
從你提供的資訊來看,這台 WordPress 主機只有約 1GB 的記憶體(961Mi),且目前已經使用了 196Mi 的 Swap。當系統開始頻繁讀寫 Swap 時,磁碟 I/O 會拖慢所有處理程序,CPU 會花費大量時間在等待 I/O 完成(iowait),這也是造成系統停擺與 CPU 滿載的常見原因。1GB 記憶體對於執行現代 WordPress 加上 Apache 來說非常吃力,建議至少提升至 2GB 以上,或嚴格限制 Apache 的進程數量。
動態請求的資源消耗
WordPress 是基於 PHP 的動態網站,每一個連線都要啟動 PHP 解釋器去抓資料庫、執行外掛程式碼,這比處理靜態網頁耗費更多資源。如果你沒有使用快取機制(如 Redis 或是 WP Super Cache),每個訪客都會對 CPU 造成直接壓力。即便你把網路隊列加長(如 somaxconn),那也只是讓訪客在「門外排隊」排得久一點,並沒有真正解決「門內的消化速度」。
改善建議
要解決排隊與 CPU 滿載問題,調整核心參數只是輔助,你需要針對軟體層優化:
- 檢查 Apache 的 mpm_event 設定,確保 MaxRequestWorkers 與你的記憶體大小匹配,避免觸發 Swap。
- 安裝 PHP 的 OPcache,這能顯著降低 CPU 處理 PHP 代碼的負擔。
- 強烈建議在 WordPress 加入物件快取(Object Cache)並搭配 Redis,減少對 MySQL 的重複查詢。
- 如果硬體資源無法提升,考慮將前端換成 Nginx 或是在 Apache 前面擋一層 Cloudflare,過濾掉不必要的壓力。
修改 prefork MPM 設定值:
nano /etc/apache2/mods-available/mpm_prefork.confprefork MPM 設定值:
StartServers 5
MinSpareServers 5
MaxSpareServers 10
MaxRequestWorkers 200
MaxConnectionsPerChild 2000記憶體過載的風險
你目前的 MaxRequestWorkers 設定為 200,這對於一台只有 1GB 記憶體的主機來說非常危險。在 prefork 模式下,每個 Apache 進程都會消耗獨立的記憶體。以 WordPress 來說,一個 PHP 進程大約佔用 40MB 到 80MB 不等。
如果同時有 200 個請求進來,記憶體需求會來到 200 x 40MB = 8000MB(約 8GB)。你的主機只有 1GB,這會導致系統強制使用硬碟當記憶體(Swap),讓 CPU 飆升到 100% 且網頁完全打不開。這就是為什麼你感覺到系統停擺的主因。
針對 1GB 記憶體的設定建議
假設扣除作業系統與其他程序佔用的 300MB,剩下約 600MB 給 Apache 使用。以每個進程 40MB 計算,MaxRequestWorkers 設定在 15 到 20 之間比較安全。
以下是建議的設定值:
StartServers 5
MinSpareServers 5
MaxSpareServers 10
MaxRequestWorkers 20
MaxConnectionsPerChild 1000設定值的邏輯說明
- MaxRequestWorkers (20):
這是最重要的防線。設定為 20 代表最多只允許 20 個連線同時進入 PHP 處理階段。雖然這會讓第 21 個人排隊,但至少能保證這 20 個人能快速拿到網頁,且不會搞垮整台主機。 - MaxConnectionsPerChild (1000):
原先的 2000 稍微偏高。調低到 1000 可以更頻繁地釋放可能洩漏的記憶體,對於小記憶體主機比較友善。 - 預留空間:
當你發現 CPU 依然很高,但記憶體還有剩時,再以每次加 5 的幅度調升 MaxRequestWorkers。
如何減少排隊感
雖然限制了進程數可以防止當機,但使用者可能會因為排隊感到緩慢。你可以嘗試以下方法緩解:
- 啟用 Page Cache:
使用外掛如 WP Rocket 或 WP Super Cache 將頁面轉為靜態 HTML。這樣 Apache 處理請求的速度會快上百倍,同樣 20 個進程能服務的總人數會大幅提升。 - 更換 MPM 模式:
如果可能,建議將 Apache 從 prefork 換成 event 模式並搭配 PHP-FPM。event 模式處理連線的效率更高,且更省記憶體。 - 檢查資料庫連線:
確保你的 WordPress 設定指向 MySQL 主機時使用的是私有 IP(例如 10.x.x.x),避免走公網造成額外的連線延遲。
Q: 2GB swap 是否太多?
Swap 的定位與影響
在 1GB 記憶體的主機上,設定 2GB 的 Swap 並不算是「太多」,但它是一把雙刃劍。當你的實體記憶體用完時,Swap 可以作為緩衝,防止系統因為記憶體不足(OOM Killer)直接強制關閉資料庫或 Apache 進程。然而,Swap 的存取速度遠慢於記憶體,一旦系統頻繁使用 Swap,整台主機的效能會劇烈下降。
從你提供的數據看,目前已經使用了 196Mi 的 Swap,這代表 1GB 的記憶體已經不夠用了。系統正在把不常用的資料搬到硬碟,如果這個數值持續跳動或增加,就是 CPU 飆高的前兆,因為 CPU 會浪費大量時間在處理記憶體與硬碟之間的資料交換。
為什麼不建議依賴大量 Swap
- 效能瓶頸:
硬碟(即使是 SSD)的速度比記憶體慢上千倍。當 Apache 請求排隊且又需要讀取 Swap 時,反應時間會從毫秒變成秒,使用者會感覺網站掛掉了。 - CPU 負擔:
管理 Swap 需要 CPU 參與,當記憶體極度短缺導致系統瘋狂交換資料(Thrashing)時,CPU 使用率會直接衝上 100%,但實際上沒有處理任何網頁請求。 - 硬碟壽命:
如果是雲端主機,頻繁的 Swap 讀寫會消耗大量的 IOPS,有些服務商會因此限制你的磁碟效能。
調整建議與優化
與其擔心 Swap 太大,不如減少系統對它的依賴。
1. 調整 Swappiness
你目前的 vm.swappiness = 10 已經是很合理的設定。這代表系統會盡可能使用實體記憶體,直到剩下約 10% 左右才會開始考慮使用 Swap。請保持這個設定。
2. 核心問題在記憶體配置
2GB 的 Swap 空間本身沒問題,問題出在你的 Apache 配置(MaxRequestWorkers 200)會輕易吃光 1GB 記憶體,強制系統去填滿那 2GB 的 Swap。這就像是雖然路邊有很大的路肩可以停車,但如果你把高速公路主線都塞滿了,車流還是會動彈不得。
3. 監控建議
你可以觀察 vmstat 1 指令中的 si (swap in) 與 so (swap out) 欄位。如果這兩個數字持續不是 0,代表系統正在發生頻繁交換,這才是真正的效能殺手。
目前的狀況下,2GB Swap 是安全的備援,但你應該透過調整 Apache 的進程數,讓 Swap 使用量維持在幾百 MB 以內甚至不使用。
apache 的 mods mpm_event 沒被 enable, 只有 enable mpm_prefork
為什麼你的主機只開啟了 mpm_prefork
在較舊的系統或預設安裝中,Apache 為了確保與 PHP 的相容性(特別是當 PHP 以 mod_php 模組運行時),會預設使用 mpm_prefork。這個模式的特色是每個請求由一個獨立的進程處理,雖然穩定,但非常耗費記憶體,這正是導致你 1GB 記憶體主機容易 CPU 100% 的根本原因。
如果你想大幅提升連線處理能力,並讓 CPU 不再輕易滿載,切換到 mpm_event 是最有效的做法。mpm_event 使用線程(threads)處理連線,能用極少的記憶體處理數倍於 prefork 的併發量。
切換到 mpm_event 的必要前提
在切換之前,你必須確認 PHP 的運行方式。mpm_event 不支援傳統的 mod_php。
安裝 PHP-FPM:你必須先安裝並啟動 php-fpm 服務。
停用 mod_php:切換 MPM 前需要先停用 PHP 模組。
更換模組:
停用 mpm_prefork:
sudo a2dismod mpm_prefork啟用 mpm_event:
sudo a2enmod mpm_event重啟 Apache:
sudo systemctl restart apache2如果決定留在 mpm_prefork 的優化
如果你因為某些舊外掛必須維持 mpm_prefork,那麼你必須嚴格執行我之前建議的 MaxRequestWorkers 20。
在 prefork 模式下,當連線數超過 MaxRequestWorkers 時,多出來的連線會進入作業系統的等待隊列(backlog)。這就是你問的「排隊等待」:
- CPU 沒滿載但要排隊:這是因為 MaxRequestWorkers 限制了同時作業的人數,門外的人在排隊,但門內的人處理很快。
- CPU 滿載且要排隊:這是因為 MaxRequestWorkers 設太大(如你原本的 200),門內擠滿了人,大家都在互搶記憶體跟磁碟 IO,導致系統接近崩潰。
總結建議
以你目前的硬體資源(1GB RAM),維持 mpm_prefork 並設定 MaxRequestWorkers 200 絕對會當機。
- 短期方案:立即將 MaxRequestWorkers 調降至 20 左右,保證系統不崩潰。
- 長期方案:改用 mpm_event 搭配 PHP-FPM。這樣同樣 1GB 的記憶體,你可能可以將 MaxRequestWorkers 開到 100 以上而不會觸發 Swap。
如何知道目前是使用 mod_php or php-fpm?
確認目前 PHP 運行方式
你可以透過以下兩種方式快速判斷:
查看 Apache 模組清單:執行指令
apache2ctl -M | grep php如果你看到 php_module 或 php7.x_module / php8.x_module,代表你正在使用 mod_php。
建立 info.php 網頁:在網頁根目錄建立一個檔案,內容寫
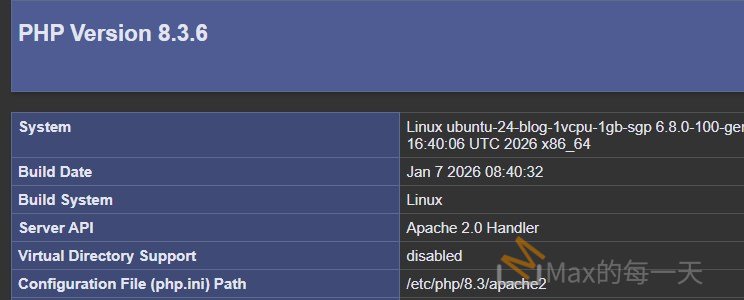
<?php phpinfo(); ?>用瀏覽器開啟後,搜尋 Server API 這一項:
如果顯示 Apache 2.0 Handler,就是 mod_php。
如果顯示 FPM/FastCGI,就是 php-fpm。
修改前: Server API: Apache 2.0 Handler
切換至 mpm_event 與 PHP-FPM 詳細步驟
假設你使用的是 PHP 8.3(請根據你的版本自行調整數字,例如 7.4 或 8.1):
1. 安裝 PHP-FPM 與相關模組
sudo apt update
sudo apt install php8.3-fpm libapache2-mod-fcgid
安裝完成後,確認 FPM 已經啟動:
sudo systemctl status php8.3-fpm
2. 啟用必要模組並停用 mod_php
這是一連串的模組切換動作,請依序執行:
# 啟用 proxy 相關模組,讓 Apache 能溝通 PHP-FPM
sudo a2enmod proxy_fcgi setenvif
# 啟用 FPM 的設定檔
sudo a2enconf php8.3-fpm
# 停用 PHP 模組 (注意版本號要對應)
sudo a2dismod php8.3
# 核心切換:停用 prefork 並啟用 event
sudo a2dismod mpm_prefork
sudo a2enmod mpm_event3. 檢查設定並重啟
在重啟前先測試設定檔是否正確:
sudo apache2ctl configtest如果顯示 Syntax OK,就重啟服務:
sudo systemctl restart apache2為什麼這能解決你的問題
切換到 mpm_event 後,Apache 不再為每個連線維持一個笨重的進程。這對你的 1GB 記憶體主機有以下好處:
- 記憶體佔用極低:Apache 進程只負責把連線傳遞給 PHP-FPM,閒置連線幾乎不佔記憶體。
- 併發能力提升:你可以安全地將同時連線數設得更高。
- 獨立管理:PHP-FPM 有自己的進程管理設定檔,你可以獨立限制 PHP 能用多少記憶體,而不會跟 Apache 搶資源。
切換完成後,原本在 /etc/apache2/mods-enabled/mpm_prefork.conf 的設定就失效了,你需要去修改 /etc/apache2/mods-enabled/mpm_event.conf。
修改用指令:
nano /etc/apache2/mods-available/mpm_event.conf針對 1GB 記憶體的 event 模式優化
切換到 mpm_event 後,你的主機體質已經大幅改善。在 event 模式下,Apache 的進程變得很輕量,主要的記憶體壓力轉移到了 PHP-FPM 手上。你提供的預設值對於 1GB 記憶體來說稍嫌激進,特別是 MaxRequestWorkers 150。如果這 150 個連線同時觸發 PHP 運算,主機依然會因為記憶體耗盡而崩潰。
以下是針對 1GB 記憶體環境的建議設定值:
StartServers 2
MinSpareThreads 25
MaxSpareThreads 50
ThreadLimit 64
ThreadsPerChild 25
MaxRequestWorkers 50
MaxConnectionsPerChild 1000設定值調整邏輯
- MaxRequestWorkers (50):雖然 event 模式很省資源,但後端的 PHP-FPM 依然很吃記憶體。將此值設為 50 是一個安全的基準,代表 Apache 最多同時送 50 個請求給 PHP 處理。這能確保在高負載時,系統仍有足夠的緩衝記憶體,不至於觸發大量的 Swap 讀寫。
- MaxSpareThreads (50):將最大閒置線程調低,可以讓 Apache 在離峰時段釋放不必要的資源。
- MaxConnectionsPerChild (1000):建議不要設定為 0(無限)。設定一個數值(如 1000)可以讓進程在處理一定量請求後重啟,有效防止長期運行可能產生的記憶體洩漏問題。
同步檢查 PHP-FPM 的設定
切換到 event 模式後,你還需要檢查 PHP-FPM 的設定檔:
nano /etc/php/8.3/fpm/pool.d/www.conf這才是決定 CPU 是否衝到 100% 的關鍵:
pm = dynamic
pm.max_children = 15
pm.process_idle_timeout = 10s
pm.start_servers = 5
pm.min_spare_servers = 5
pm.max_spare_servers = 10
pm.max_requests = 500
- pm.max_children (20):這限制了同時運行的 PHP 進程數。因為每個 PHP 進程大約 40-60MB,20 個大約佔用 1GB 左右的空間。這個數值應與 Apache 的 MaxRequestWorkers 搭配。如果你發現記憶體還有剩餘,可以慢慢往上加。 反之,如果設了 20 還是占用掉大量 swap 就要降低。
觀察成效
完成設定後,請重啟服務:
sudo systemctl restart php8.3-fpm apache2你可以觀察 top 或 htop。如果 CPU 負載下降且 Swap 使用量不再增加,代表目前的平衡點是正確的。如果使用者仍反映要排隊,但 CPU 很閒,再逐步調高 pm.max_children 與 MaxRequestWorkers。
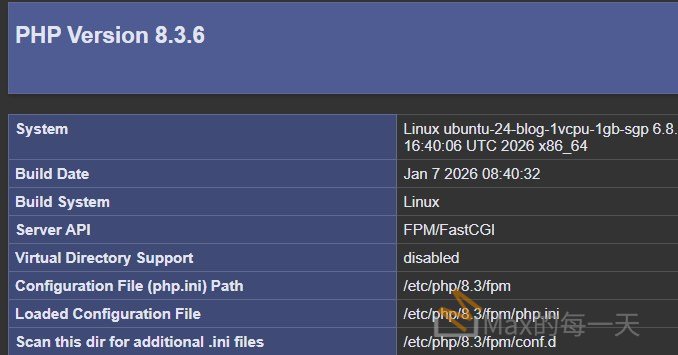
修改之後: Server API: FPM/FastCGI
計算單個 PHP 進程的記憶體平均值
要精確設定 pm.max_children,你需要知道每個 PHP 進程實際上吃了多少記憶體。請在終端機執行以下指令:
ps -ylC php-fpm8.3 --sort:rss | awk '{sum+=$8; ++n} END {if (n > 0) print sum/n/1024 " MB"}'
(請根據你的版本修改 php-fpm8.3)
這條指令會抓取所有正在執行的 PHP-FPM 進程,並計算出平均每個進程佔用的實體記憶體(RSS)。
如何根據結果調整 pm.max_children
得到平均值後,你可以使用以下公式來估算:
(可用記憶體 - 系統預留) / 單個 PHP 進程平均大小 = pm.max_children
舉例來說:
- 可用記憶體:1024MB
- 系統預留(作業系統 + Apache + MySQL):400MB
- 剩餘空間:624MB
- 如果你的 PHP 進程平均是 40MB,則 $624 / 40 = 15.6$。
- 建議設定:pm.max_children = 15。
優化 PHP-FPM 與 Apache 的連動
當你設定好 pm.max_children 後,Apache 的 MaxRequestWorkers 應該設為與其相同或略大一點。如果 pm.max_children 設得太小,Apache 送過去的請求會因為沒有多餘的 PHP 工人處理而在後台排隊,這就是為什麼 CPU 沒滿但使用者要等待的原因之一。
其他關鍵優化
為了讓這 1GB 記憶體發揮最大效益,請檢查以下設定:
- pm.max_requests:在
www.conf中將此值設為 500 或 1000。這會讓 PHP 進程在處理完固定次數請求後重啟,能有效清理記憶體殘留,對小主機非常重要。 - opcache:確保
/etc/php/8.3/fpm/php.ini中的opcache.enable=1與opcache.memory_consumption=128是開啟的。這能大幅降低 CPU 負擔。 - MySQL 檢查:你的 WordPress 與 MySQL 分開兩台,這很好。但請確保 WordPress 那台主機的
wp-config.php是使用私有 IP 連線,避免 DNS 解析或公網延遲拖慢 PHP 進程的存活時間。
為什麼預設 /etc/php/8.3/fpm/php.ini 中的 opcache.enable 沒被啟用?
PHP FPM 與 OPcache 的預設行為
在多數 Linux 發行版(如 Ubuntu 或 Debian)中,當你透過套件管理員安裝 PHP 8.3 時,你會發現 php.ini 檔案裡的 opcache.enable 前面標註了分號,這代表該行是被註釋掉的。雖然在 php.ini 檔案中看起來像是沒啟用,但實際上 OPcache 在 FPM 環境下通常是運行的。
這是因為 PHP 的設定採用了模組化管理。在 /etc/php/8.3/fpm/conf.d/ 目錄下,會有一個類似 10-opcache.ini 的符號連結,它指向 /etc/php/8.3/mods-available/opcache.ini。在這個獨立的設定檔中,通常已經包含了 zend_extension=opcache.so 以及 opcache.enable=1。
PHP 在啟動時會先讀取主 php.ini,接著讀取 conf.d 目錄下的所有額外設定。由於 conf.d 中的設定載入順序較晚,它會覆蓋掉 php.ini 裡的預設值。
為什麼不直接在主設定檔啟用
這種設計主要是為了維護的便利性。透過將不同擴充功能的設定拆分到獨立檔案,系統管理員可以簡單地使用 phpenmod 或 phpdismod 指令來開啟或關閉特定功能,而不需要去更動核心的 php.ini 檔案。
如果 opcache.enable 在 php.ini 中被硬編碼啟用,當你想暫時停用它來進行除錯時,操作會變得比較麻煩。模組化的做法讓升級 PHP 版本時,設定檔的遷移與管理變得更加直覺,也能避免主設定檔變得過於臃腫。
如果你想確認目前 OPcache 是否真的有在運作,可以撰寫一個包含 phpinfo(); 內容的檔案並透過瀏覽器執行,或者在終端機輸入 php-fpm8.3 -i | grep opcache.enable 來查看最終生效的數值。
指令實際執行畫面:
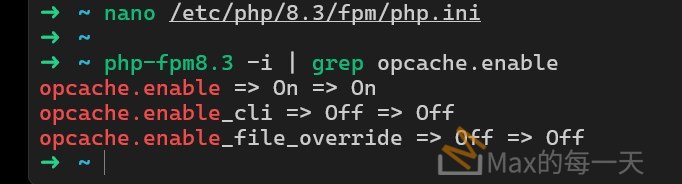
opcache.enable 在 php.ini 裡, 是被註解沒啟用, 實際上是有被 enable
如何在負載測試期間(例如使用 ab 工具)監控記憶體與 Swap 的即時變化?
即時監控與測試方法
要找出系統的極限,最有效的方法是在模擬負載時觀察資源變化。你可以使用 Apache 內建的 $ab$ (Apache Benchmark) 工具,從外部或另一台主機進行測試。
1. 準備監控視窗
建議同時開啟兩個終端機視窗:
視窗 A(觀察記憶體與 Swap): 執行
watch -n 1 free -m這讓你每秒看到記憶體減少與 Swap 增加的速度。
視窗 B(觀察 PHP 進程): 執行
watch -n 1 "ps aux | grep php-fpm | grep -v grep | wc -l"這能讓你確認 pm.max_children 是否已經達到上限。
使用 ab 進行壓力測試
在另一台電腦執行以下指令(不要在 WordPress 主機自己跑,會影響測試準確性):
ab -n 500 -c 20 http://你的網站IP/
-n 500:總共發出 500 個請求。-c 20:同時有 20 個連線(併發)。
測試時的觀察重點:
- 情境 1: 如果 Swap 數字開始快速跳動,代表
pm.max_children設得太高,記憶體爆了。 - 情境 2: 如果
free顯示記憶體還有剩,但ab測試結果很慢,且 PHP 進程數卡在 20 不動,代表你的pm.max_children設太低,CPU 沒事做但大家在排隊。
count children = 10, each thread 127MB 已大於該 VPS 的 1GB RAM.
找出完美的平衡點
理想的狀態是:當併發連線進來時,CPU 使用率上升(代表有在做事),實體記憶體用到約 80%~90%,但 Swap 幾乎不動。
如果你的測試結果顯示 CPU 還是很容易衝到 100%,即使記憶體夠用,那通常是因為 WordPress 處理每個請求的時間太長。這時你需要檢查:
- MySQL 慢查詢: 檢查 MySQL 主機是否因為沒有索引導致查詢變慢,拖住 PHP 進程。
- Object Cache: 在 WordPress 安裝 Redis Object Cache 插件。這能讓原本需要 0.5 秒處理的頁面縮短到 0.1 秒,同樣的進程數就能服務 5 倍的使用者。
記憶體共享機制與計算誤差
這是一個非常經典的誤區。雖然指令算出的平均值是 127MB,但這 10 個進程並不是真的佔用了
10 x 127 = 1270MB
1. 共享記憶體 (Shared Memory)
PHP-FPM 的主進程啟動時,會載入 PHP 核心、擴充功能和常用代碼(特別是開啟 OPcache 後)。當它產生子進程(Workers)時,這些子進程會共享主進程已經載入的唯讀記憶體區塊。
ps 指令算出的 RSS(Resident Set Size)包含了進程自己獨有的資料以及它跟別人共享的資料。如果你把每個進程的 RSS 全部加總,會重複計算那些「共享的部分」,導致總數看起來超過了實體記憶體。
2. 為什麼系統沒崩潰
從你的 free -m 來看,used 是 678Mi,這才是系統目前真正消耗的實體記憶體。扣除掉快取後,你的 available 還有 282Mi。這代表這 10 個 PHP 進程實際上扣除掉彼此重複的部分,總共只佔用了大約 400 到 500MB 左右。
3. 127MB 的警訊
雖然有共享機制,但平均每個進程 127MB 在 WordPress 裡算是偏肥大的。這通常代表:
- 你安裝了較多或較大型的外掛。
- 你的主題(Theme)載入了大量函式庫。
- 這些進程在處理完請求後,還沒釋放某些動態生成的資料。
如何更精準地觀察與調整
1. 使用 PSS 計算(更準確)
如果你想看扣除共享後「真正」佔用的記憶體,可以試試安裝 smem 工具,它計算的 PSS (Proportional Set Size) 會把共享記憶體平攤給每個進程,算出來的總和才等於系統實際消耗量。
2. 調整 pm.max_requests
你的進程長到 127MB,有可能是因為處理過太多請求而累積了碎片。在 www.conf 裡設定:
pm.max_requests = 500這能強迫進程在處理 500 次請求後重啟,把記憶體歸零,防止它無限制長大到真的塞爆 RAM。
3. 修正 pm.max_children
根據你現在 127MB 的觀察值,即便有共享,我也建議你的 pm.max_children 最多設 10 到 12 就好。因為在高負載下,每個進程處理複雜查詢時,獨有的記憶體會迅速增加,那時共享部分的比例會下降,如果不限制數量,136Mi 的 Swap 很快就會變成 500Mi,到時 CPU 就會衝上 100%。
你想確認目前 www.conf 裡的 pm 模式是 static 還是 dynamic 嗎?這會影響這 10 個進程是否會自動增減。
雖然把數值調低, 在 CPU / RAM / Disk IO 都明顯下降,但實際上造成的平均反應時間是大大的上升,所以讓 CPU / RAM 微微滿載,可能可以再降低一點回應時間。
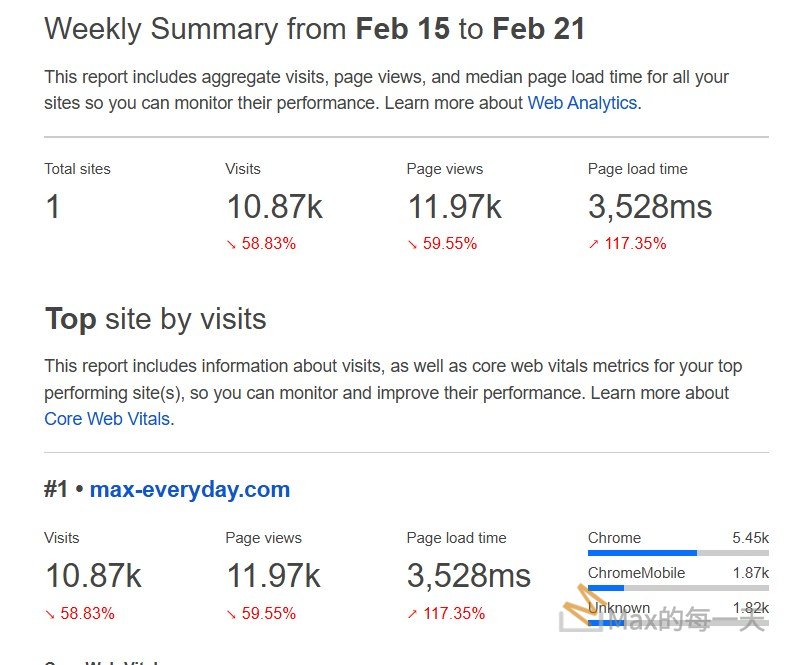
page views 下降,且page load time 還上升,也許不去調整,performance 才是更好的, 呵呵。