從其他網頁上收集到的資訊來看,應該多去使用免費的TPU,因為執行的時間有可能只需要原本的訓練時間的 1/3, 缺點是程式碼需要一點點的微調。參考網頁說明:
Colab提供了免費TPU
https://www.itread01.com/elpqhk.html
參考性佳的範例:
Getting Started with PyTorch on Cloud TPUs
https://medium.com/pytorch/get-started-with-pytorch-cloud-tpus-and-colab-a24757b8f7fc
Get started with our Colab Tutorials
- Getting Started with PyTorch on Cloud TPUs
- Training AlexNet on Fashion MNIST with a single Cloud TPU Core
- Training AlexNet on Fashion MNIST with multiple Cloud TPU Cores
- Fast Neural Style Transfer (NeurIPS 2019 Demo)
- Training A Simple Convolutional Network on MNIST
- Training a ResNet18 Network on CIFAR10
- ImageNet Inference with ResNet50
- PyTorch/XLA Performance Profiling
Note: These colab notebooks typically run on small machines (the Compute VMs, which runs the input pipeline) and training is often bottlenecked on the small Compute VM machines. For optimal performance create a GCP VM and TPU pair following our GCP Tutorials:
- Training FairSeq Transformer on Cloud TPUs
- Training Resnet50 on Cloud TPUs
- Training PyTorch models on Cloud TPU Pods
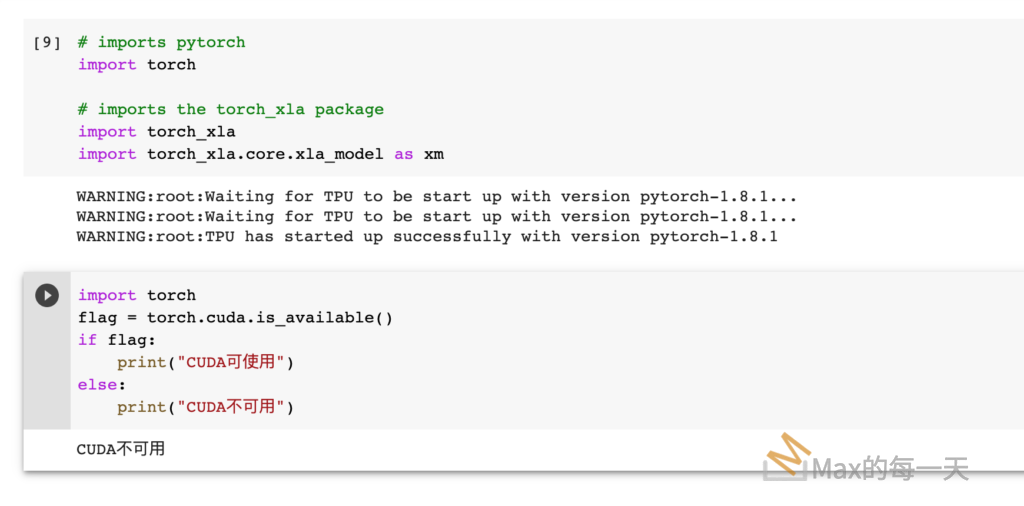
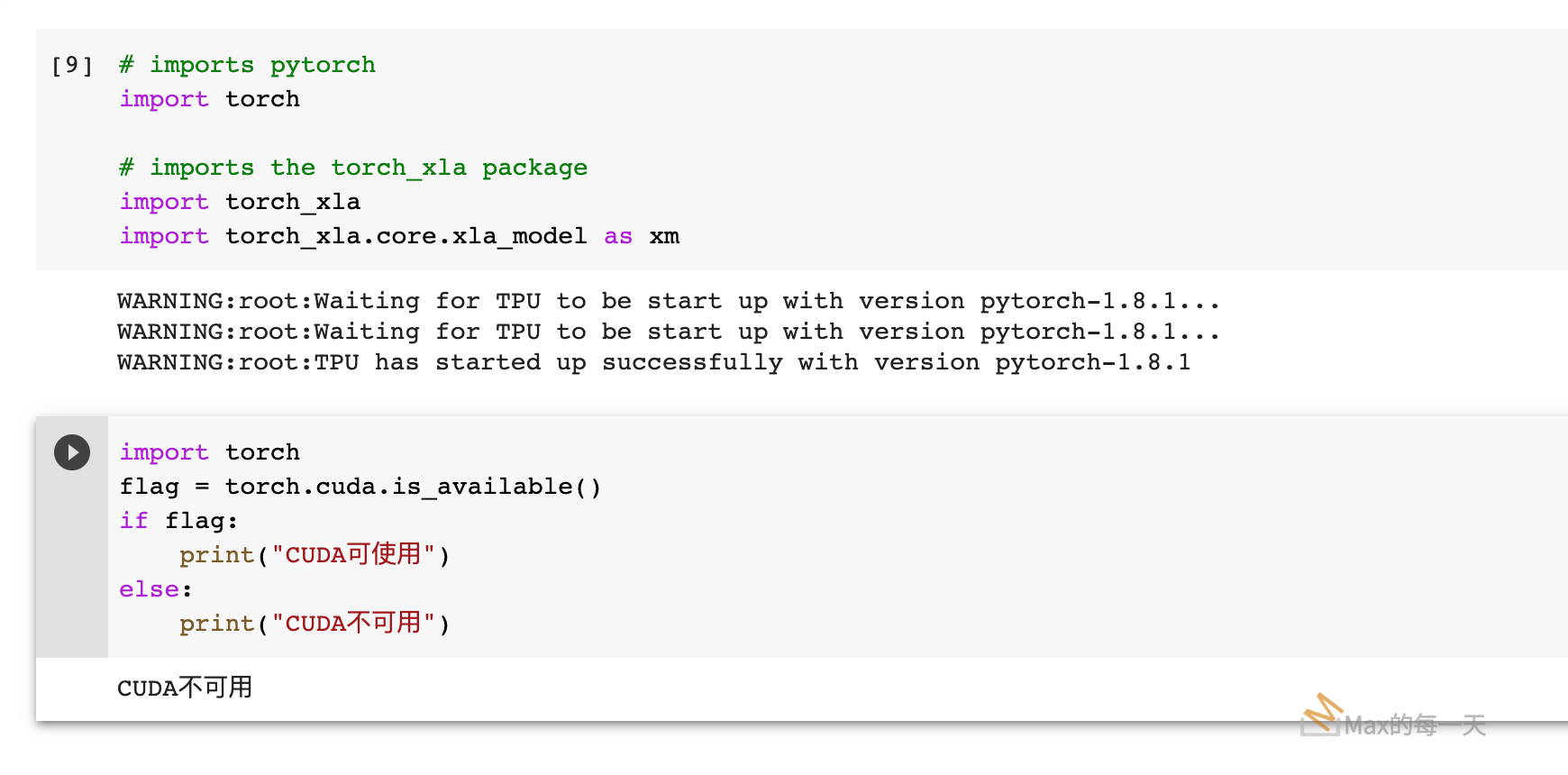
實際測試結果,在 import xla_model 時,可以看到去初始化 TPU的訊息,最後成功取得 TPU 資源。
TPU 與 cuda 似乎是不同的世界,所以 CUDA 沒被啟用。