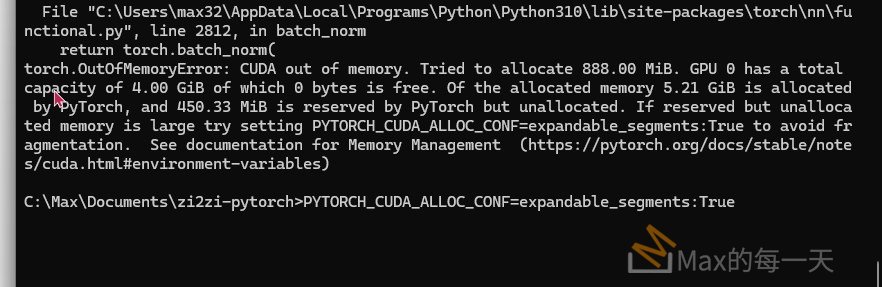
這裡是包含 Residual Block 的完整 UNetGenerator Python 腳本,適用於 Noto Sans → Zen Maru Gothic 的字型風格轉換。
主要改動
- 加入 Residual Block
- 在
UnetSkipConnectionBlock的 Encoder(下採樣部分)加入 ResNet-style 跳躍連接,提升特徵傳遞效果。 - 殘差連接(Residual Connection) 有助於深層網路的梯度流動,避免訊息遺失。
- 在
- 改進 UNet 架構
- 在中間層(如
layer=3,4,5)使用 Residual Block。 - 選擇性加入 Self-Attention 來增強風格細節學習。
- 在中間層(如
完整 UNet Generator(含 Residual Block)
import torch
import torch.nn as nn
import torch.nn.functional as F
# ------------------------
# Residual Block
# ------------------------
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.norm1 = nn.InstanceNorm2d(in_channels)
self.conv2 = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.norm2 = nn.InstanceNorm2d(in_channels)
def forward(self, x):
identity = x # 保留原始輸入
out = self.conv1(x)
out = self.norm1(out)
out = F.relu(out, inplace=True)
out = self.conv2(out)
out = self.norm2(out)
return out + identity # 殘差連接
# ------------------------
# Self-Attention Module
# ------------------------
class SelfAttention(nn.Module):
def __init__(self, in_channels):
super(SelfAttention, self).__init__()
self.query = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)
self.key = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)
self.value = nn.Conv2d(in_channels, in_channels, kernel_size=1)
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
batch_size, C, width, height = x.size()
proj_query = self.query(x).view(batch_size, -1, width * height).permute(0, 2, 1) # (B, N, C//8)
proj_key = self.key(x).view(batch_size, -1, width * height) # (B, C//8, N)
energy = torch.bmm(proj_query, proj_key) # (B, N, N)
attention = F.softmax(energy, dim=-1)
proj_value = self.value(x).view(batch_size, -1, width * height) # (B, C, N)
out = torch.bmm(proj_value, attention.permute(0, 2, 1)) # (B, C, N)
out = out.view(batch_size, C, width, height)
out = self.gamma * out + x # 殘差連接
return out
# ------------------------
# UNet Skip Connection Block
# ------------------------
class UnetSkipConnectionBlock(nn.Module):
def __init__(self, outer_nc, inner_nc, input_nc=None, submodule=None,
use_attention=False, use_residual=False, norm_layer=nn.InstanceNorm2d, layer=0):
super(UnetSkipConnectionBlock, self).__init__()
outermost = (layer == 8)
innermost = (layer == 1)
self.outermost = outermost
self.innermost = innermost
self.layer = layer
self.use_attention = use_attention
self.use_residual = use_residual
use_bias = norm_layer == nn.InstanceNorm2d # 只在 InstanceNorm2d 時使用 bias
self.norm_layer = norm_layer
if input_nc is None:
input_nc = outer_nc
# Downsampling
self.down = nn.Conv2d(input_nc, inner_nc, kernel_size=4, stride=2, padding=1, bias=use_bias)
self.down_norm = norm_layer(inner_nc) if not outermost else nn.Identity()
# Upsampling
if outermost:
self.up = nn.ConvTranspose2d(inner_nc * 2, outer_nc, kernel_size=4, stride=2, padding=1)
self.up_norm = nn.Identity()
elif innermost:
self.up = nn.ConvTranspose2d(inner_nc, outer_nc, kernel_size=4, stride=2, padding=1, bias=use_bias)
self.up_norm = norm_layer(outer_nc)
else:
self.up = nn.ConvTranspose2d(inner_nc * 2, outer_nc, kernel_size=4, stride=2, padding=1, bias=use_bias)
self.up_norm = norm_layer(outer_nc)
# 加入 Residual Block
if use_residual and not outermost:
self.res_block = ResidualBlock(inner_nc)
if use_attention:
self.attn = SelfAttention(inner_nc)
self.submodule = submodule
def forward(self, x):
down_x = self.down(x)
if not self.outermost:
down_x = self.down_norm(down_x)
down_x = F.leaky_relu(down_x, 0.2, inplace=True)
# 加入 Residual Block
if self.use_residual and not self.outermost:
down_x = self.res_block(down_x)
# 加入 Self-Attention
if self.use_attention and not self.outermost:
down_x = self.attn(down_x)
if self.submodule is not None:
down_x = self.submodule(down_x)
up_x = self.up(down_x)
up_x = self.up_norm(up_x)
if self.outermost:
return up_x
else:
up_x = F.relu(up_x, inplace=True)
return torch.cat([up_x, x], dim=1)
# ------------------------
# UNet Generator
# ------------------------
class UNetGenerator(nn.Module):
def __init__(self, input_nc=1, output_nc=1, num_downs=8, ngf=64,
use_attention=True, use_residual=True, norm_layer=nn.InstanceNorm2d):
super(UNetGenerator, self).__init__()
# 最內層(bottleneck)
unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, norm_layer=norm_layer, layer=1)
# 中間層
for index in range(num_downs - 5):
loop_use_attention = use_attention and (index + 2 == 4)
loop_use_residual = use_residual
unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, submodule=unet_block,
norm_layer=norm_layer, use_attention=loop_use_attention,
use_residual=loop_use_residual, layer=index + 2)
unet_block = UnetSkipConnectionBlock(ngf * 4, ngf * 8, submodule=unet_block, norm_layer=norm_layer, layer=5)
unet_block = UnetSkipConnectionBlock(ngf * 2, ngf * 4, submodule=unet_block, norm_layer=norm_layer,
use_attention=use_attention, use_residual=use_residual, layer=6)
unet_block = UnetSkipConnectionBlock(ngf * 1, ngf * 2, submodule=unet_block, norm_layer=norm_layer, layer=7)
# 最外層
self.model = UnetSkipConnectionBlock(output_nc, ngf * 1, input_nc=input_nc, submodule=unet_block,
norm_layer=norm_layer, layer=8)
def forward(self, x):
output = self.model(x)
output = torch.tanh(output) # 使用 Tanh 縮放輸出到 [-1, 1]
return output
改進點
✅ 加入 Residual Block,減少梯度消失
✅ 在 Encoder 層中選擇性加入 Self-Attention
✅ 更穩定的梯度流,使風格轉換效果更佳 🚀
這樣的 UNet 結構適合字型風格轉換,能夠更有效地學習 Zen Maru Gothic 的平滑筆劃風格!