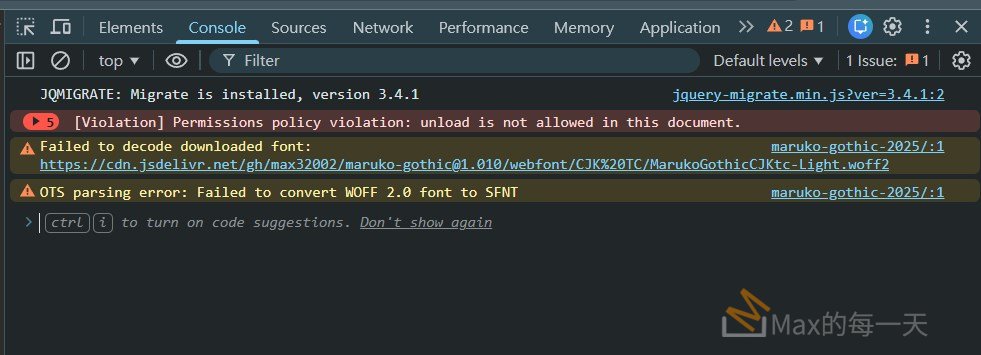
遇到這個問題, 真的很玄, 同時做了3個語系(cjk jp/ cjk tc / cjk sc), 字元數目在這3個語系是一樣多, 產生的檔案檔大小, 不確定是不是因為先刪掉原本 cjk jp 的字, 再使用 merge 匯入新造的字, 誤刪了一些被 alt 進行引用的字, 所以產生出來的 woff2 是錯誤的.
神奇的是, 直接 convert 成 woff 格式, 檔案又是正常的.
改用 fontforge 以外的工具進行 woff2 格式轉換, 結果也一樣.
最快的懶人解法, 是只匯出特定範圍的字元到 woff2, 就解決了:
pyftsubset MarukoGothic.ttf ^
--unicodes="U+0000-007F,U+00A0-00FF,U+2000-206F,U+3000-303F,U+3040-309F,U+30A0-30FF,U+4E00-9FFF,U+FF00-FFEF" ^
--flavor=woff2 ^
--layout-features="*" ^
--output-file=MarukoGothic_optimized.woff2詳細說明: TTF 轉 WOFF2 工具
https://codereview.max-everyday.com/ttf-to-woff2/