Numpy 和 Pandas 似乎變成必學的套件,用在數字處理上有顯著的貢獻。
今天要分享的文章:
提升 pandas 80% 效率秘訣大公開
https://medium.com/@t0915290092/%E5%A6%82%E4%BD%95%E8%A7%A3%E6%B1%BA-pandas-%E6%95%88%E7%8E%87%E7%B7%A9%E6%85%A2%E7%9A%84%E5%95%8F%E9%A1%8C-7466b3e996df
這篇文章的重點:
- Pandas 是如何運用 Numpy 提高效能的
- 還能運用什麼方式幫助 Pandas 讓他跑得更快
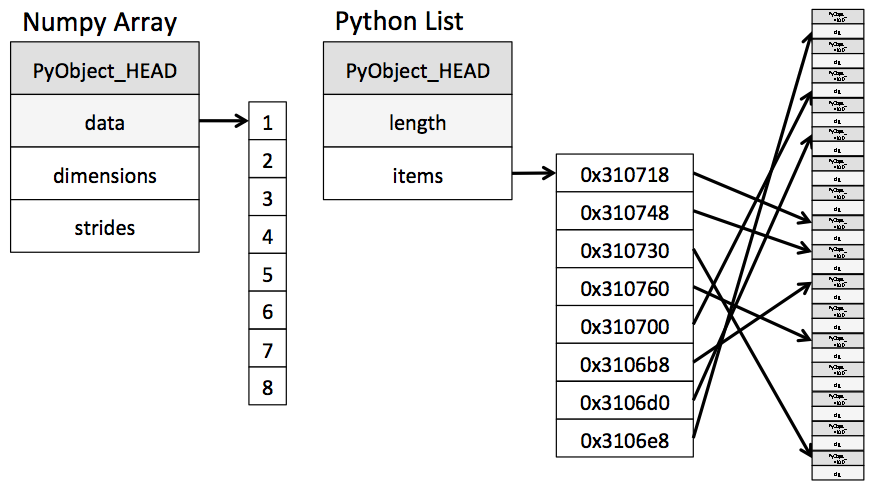
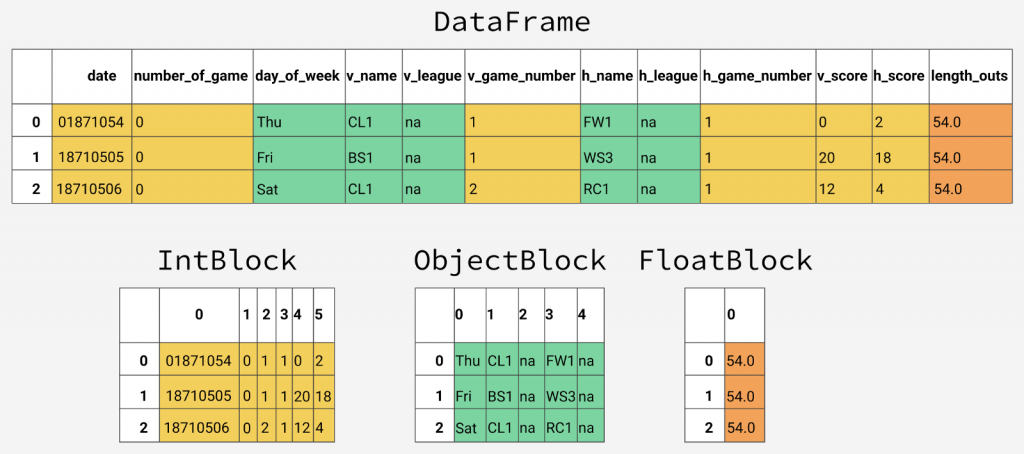
文章論點來自這2張圖:
其他網友的論點:
Chen Chia Ming 您做的是將資料型態降級,得到記憶體的用量縮減是必然的事.但跟”實際運算效能”能否得到提昇是兩回事,貿然將資料型態降級雖然有助於減少記憶體,但在運算上非常可能造成有效位元數不足而產生溢位問題或必須另外提升位元數,對計算上不見得有幫助….float64降成float32也是存在著有效位元數下降問題,在進行運算上可能會產生捨位誤差. ….
對於重覆字串,轉成category 的確也可以省下記憶體,但應視資料屬性而定,如果字串資料本身就是偏向類別型態(如性別,顏色),那轉成category 是個好的選擇, 但若字串資料本身不具類別型態(如姓名),而且可能進行字串運算,那就不應該轉成category。
Max Yao 在記憶體夠用的情況下,降級只有解決字串處理緩慢,相對快造成無法進行字串處理。