Youtube 有提供 playlist 的功能, 針對別人分享的 play list 如何重新取得與整理?
在 chrome 瀏覽器, 連到 youtube 的某一個 playlist 按右鍵選擇 inspect,
應該是在 <div id=”items”> 按右鍵, 選擇 “Copy” -> “Copy element” 就可以取得 html 內容.
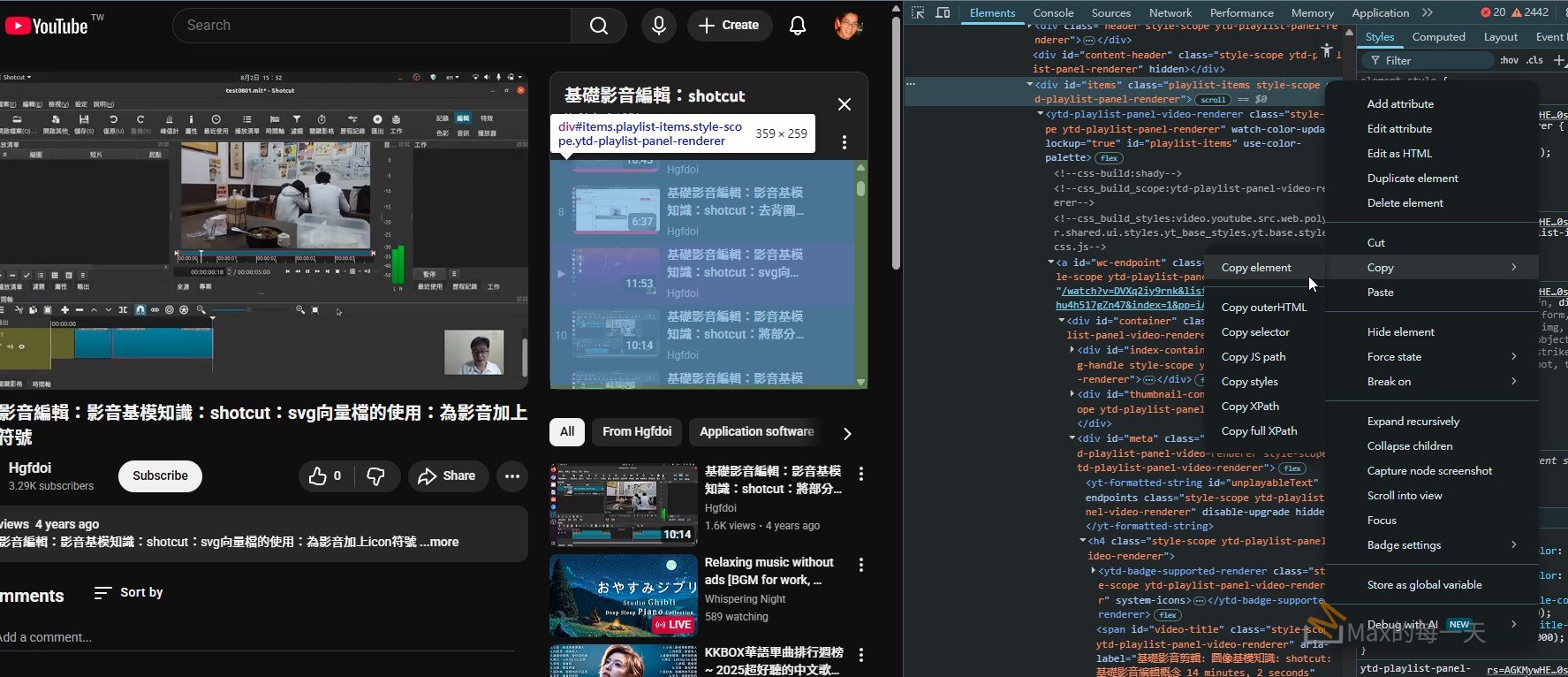
創建一個文字檔, 叫 list.html, 並貼上 html 內容,
取代內容中的 href="/watch?v= 為:
href="https://www.youtube.com/watch?v=環境的準備:
pip install BeautifulSoup4建立一個檔案 parse_yt_playlist.py :
import os
from bs4 import BeautifulSoup
def extract_youtube_info(input_filename="list.html", output_filename="output.txt"):
"""
讀取 HTML 檔案內容,擷取連結和標題,並輸出到螢幕和指定文字檔案。
"""
# 1. 讀取 list.html 檔案內容
try:
with open(input_filename, 'r', encoding='utf-8') as f:
html_content = f.read()
except FileNotFoundError:
print(f"錯誤:找不到檔案 '{input_filename}'。請確定檔案存在於程式碼相同目錄。")
return
except Exception as e:
print(f"讀取檔案時發生錯誤: {e}")
return
# 2. 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(html_content, 'html.parser')
results = []
# 3. 尋找所有影片項目的最外層容器:<ytd-playlist-panel-video-renderer>
video_blocks = soup.find_all('ytd-playlist-panel-video-renderer')
# 4. 依序迴圈處理每個影片 block
for block in video_blocks:
# 4a. 擷取 <a id="wc-endpoint"> tag 中的 href 屬性
endpoint_tag = block.find('a', id='wc-endpoint')
href_link = "找不到 href"
if endpoint_tag and 'href' in endpoint_tag.attrs:
href_link = endpoint_tag['href']
# 4b. 擷取 <span id="video-title"> tag 的 text 內容
title_tag = block.find('span', id='video-title')
title_text = title_tag.get_text(strip=True) if title_tag else "找不到標題"
# 將結果儲存
results.append({
'href': href_link,
'title': title_text
})
# 5. 格式化輸出內容
output_lines = []
output_lines.append("--- 擷取結果 ---")
for i, item in enumerate(results, 1):
output_lines.append(f"影片 {i}:")
output_lines.append(f" 連結 (href): {item['href']}")
output_lines.append(f" 標題 (text): {item['title']}")
output_lines.append("-" * 20)
# 將所有行合併成單一字串
output_content = "\n".join(output_lines)
# 6. 輸出到文字檔案
try:
with open(output_filename, 'w', encoding='utf-8') as f:
f.write(output_content)
print(f"\n已成功將結果輸出到檔案: {output_filename}")
except Exception as e:
print(f"\n寫入檔案 '{output_filename}' 時發生錯誤: {e}")
# 7. 輸出到螢幕
print("\n" + output_content)
if __name__ == "__main__":
extract_youtube_info("list.html")執行上面的 python 檔案:
python parse_yt_playlist.py這時候, 除了畫面輸出之外, 也會輸出到 output.txt
確定畫面上的輸出內容都正確之後, 把 output.txt 改檔名為: list.txt
再建立一個新檔案, format_yt_playlist.py:
import os
def format_video_list(input_filename="list.txt", output_filename="formatted_output.txt"):
"""
讀取指定的輸入文字檔案,解析影片連結和標題,將其重新格式化為
<li><a href={連結 (href)}>{連結 (href)}{標題 (text)}</a></li> 的 HTML 格式,
並將結果同時輸出到螢幕和指定的輸出檔案。
"""
# 檢查輸入檔案是否存在
if not os.path.exists(input_filename):
print(f"錯誤:找不到輸入檔案 '{input_filename}'。請確認檔案是否存在。")
return
formatted_output = []
current_link = None
current_title = None
try:
# 讀取輸入檔案
with open(input_filename, 'r', encoding='utf-8') as f:
for line in f:
stripped_line = line.strip()
# 忽略空白行或影片編號行
if not stripped_line or stripped_line.startswith("影片"):
continue
# 檢查並擷取連結 (href)
link_key = "連結 (href):"
if stripped_line.startswith(link_key):
current_link = stripped_line[len(link_key):].strip()
# 檢查並擷取標題 (text)
title_key = "標題 (text):"
if stripped_line.startswith(title_key):
current_title = stripped_line[len(title_key):].strip()
# 當連結和標題都已擷取到時,執行格式化並儲存
if current_link and current_title:
# 格式化為 <li><a href="{連結}">{連結}{標題}</a></li>
html_string = (
f"<li>{current_title}</br><a href=\"{current_link}\">"
f"{current_link}"
f"</a></li>"
)
formatted_output.append(html_string)
# 重置變數以準備處理下一組影片資料
current_link = None
current_title = None
except Exception as e:
print(f"讀取或處理輸入檔案時發生錯誤: {e}")
return
# 輸出結果到螢幕 (標準輸出)
print("--- 重新格式化結果 (輸出到螢幕) ---")
for item in formatted_output:
print(item)
print("-----------------------------------")
# 將結果寫入輸出檔案
try:
with open(output_filename, 'w', encoding='utf-8') as outfile:
outfile.write('<ol>\n')
for item in formatted_output:
outfile.write(item + '\n')
outfile.write('</ol>\n')
print(f"\n成功將 {len(formatted_output)} 條記錄寫入檔案: '{output_filename}'")
except Exception as e:
print(f"寫入輸出檔案 '{output_filename}' 時發生錯誤: {e}")
# 執行函式
format_video_list()執行上面的 python 檔案:
python format_yt_playlist.py執行結果:
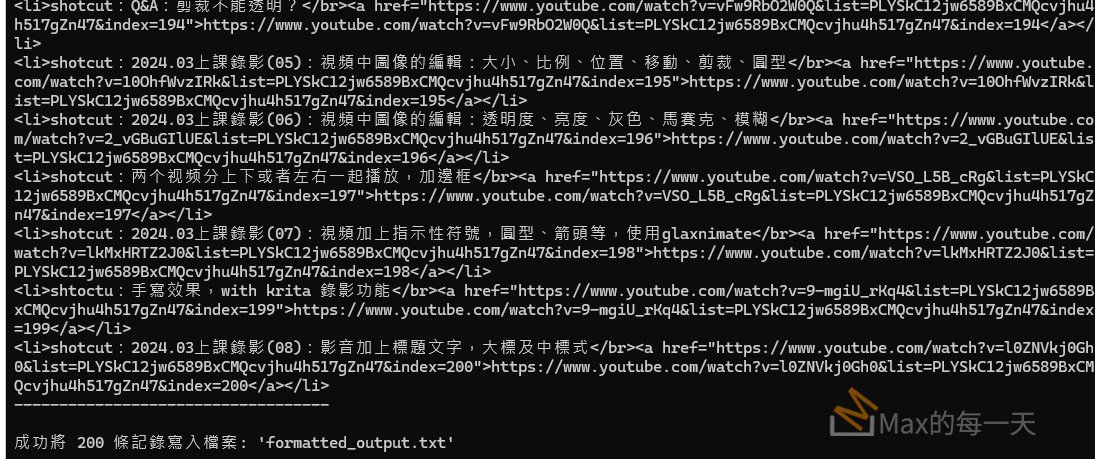
就可以取得重新 html 格式化的內容, 顯示效果如下:

未來似乎還可以再加上 youtube 的 thunbnail, 視覺效果會更好.