情境是有多欄位的資料, 中間分隔是以空格, 但可能有多個空格, 自己做比較慢, python 已有內建的 io 可以處理字串.
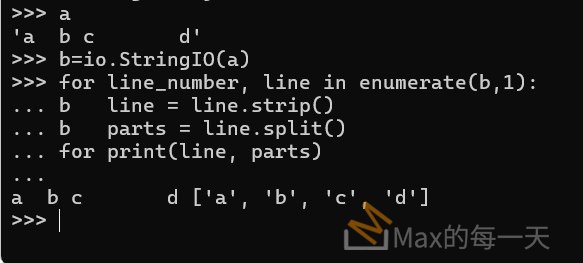
範例說明: a 與 b 相隔2個空格, b 與 c 相隔 1 空格, c 與 d 相隔 N 個空格, 最終取得4個元素.
範例:
data_normalized = cookie_data.replace(' ', '\t')
file_like_object = io.StringIO(data_normalized)
for line_number, line in enumerate(file_like_object, 1):
line = line.strip()
if not line or line.startswith('#'):
continue
parts = line.split()
這個範例說, # 開頭的行, 資料不要, 其他的分隔後放入 parts array.
完整範例, 轉換 string 為 dicttionary
def parse_netscape_cookies(cookie_data):
data_normalized = cookie_data.replace(' ', '\t')
file_like_object = io.StringIO(data_normalized)
cookies_list = []
FIELD_NAMES = [
"domain",
"subdomains",
"path",
"secure",
"expiration",
"name",
"value"
]
for line_number, line in enumerate(file_like_object, 1):
line = line.strip()
if not line or line.startswith('#'):
continue
parts = line.split()
# 預期會有 7 個欄位,如果分割結果不足 7 個,則表示解析錯誤或格式不完整
if len(parts) < 7:
print(f"\n[⚠️ 警告] 第 {line_number} 行格式不完整,跳過:{line}")
continue
cookie_fields = {
"Line": line_number,
FIELD_NAMES[0]: parts[0], # Domain
FIELD_NAMES[1]: to_bool(parts[1]), # Include Subdomains (Flag)
FIELD_NAMES[2]: parts[2], # Path
FIELD_NAMES[3]: to_bool(parts[3]), # Secure (Flag)
FIELD_NAMES[4]: int(parts[4]), # Expiration Timestamp
FIELD_NAMES[5]: parts[5], # Name
FIELD_NAMES[6]: parts[6], # Value
}
cookies_list.append(cookie_fields)
return cookies_list